读到一篇关于强化学习在机器人manipulation的应用综述, Review of Deep Reinforcement Learning for Robot Manipulation 。分享一下。
0、摘要
强化学习与神经网络相结合,最近在不同领域取得了广泛的成功。对于机器人manipulation,强化学习算法通过直接从原始图像中学习灵巧manipulation,为机器带来了具有类人能力的希望。在这篇综述文章中,我们介绍了该领域中使用的强化学习算法的当前状况。我们还将介绍当前算法的基本理论背景和主要问题,这些问题限制了强化学习算法在解决机器人技术实际问题中的应用。我们还就加强学习研究的许多未来方向分享了我们的想法。
1、介绍
近年来,强化学习(RL)引起了很多关注[1] – [3], 在多个领域都取得了令人兴奋的成果,例如超越了Atari 游戏的人类专家 [4] 和围棋游戏[5]。在机器人操作环境中,RL可以直接从原始图像端对端学习灵巧操作。该领域的最初成功是令人鼓舞的,但是,它们揭示了应用RL解决实际机器人挑战的一些固有困难。综述旨在提供我们在机器人manipulation中使用RL的体会与理解。我们尝试涵盖背景知识,有趣的研究成果,未解决的问题,并提供我们对未来方向的预见。
在[6]中已全面涵盖了今年之前机器人技术中使用的 大多数先前RL算法。据我们所知,从今年开始,不管有多少有趣的方法,RL在机器人操纵方面都没有进行重大review。 我们试图通过本文的回顾来补充,重点放在RL在机器人manipulation上的应用。我们在著名电子数据库中进行了广泛的文献搜索。符合以下条件的文章将包括在内:a)用英语写; b)从2013年起出版;c)仅在与会议文件有重大差异时才包括期刊出版物;d)内容与用于机器人manipulation的DRL有 关。用于搜索的关键词是reinforcement learning, deep reinforcement learning, and robot manipulation。我们的论文安排如下:从第二部分开始,我们将描述RL的关键概念。接下来,第三节继续介绍RL算法的分类,接着是第四节,重点关注机器人操作。 我们在第五节中描述了对未来方向的观点,第六节总结。
2、关键概念
这一部分主要讲了什么是强化学习,请看其他技术博客,论文里讲的不如其他技术博客清楚,就不详细介绍了。
3、分类
本文将其分为:Model-based vs Model-free and policy-based vs Value-based algorithms。
Model-based vs Model-free
我们可以通过确定agent是否了解环境模型来划分可用的RL算法。 了解模型可以使agent提前知道状态转移概率矩阵和未来的reward。此功能使agent可以预测从一系列可能的操作中选择某个操作时,将发生的情况。如果模型正确,则与无模型方法相比,该方法将大大提高样本效率。但是,通常情况是模型不可用或学习此类模型非常困难。学习到的代理可能会表现出色模型,但在实际环境中可能表现欠佳甚至表现不佳。无模型方法专注于直接从与环境的交互中找出value function。此类中的算法严重依赖reward 来学习值函数。因此,具有学习reward的功能很重要。 此外,它们通常更易于实现和调整超参数。当前,由于这些优点,与基于模型的方法相比,无模型方法的使用频率更高。
policy-based vs Value-based
基于策略的方法大多是on-policy的,这意味着他们同时使用policy进行控制和估计value。因此他们只使用了最新版本的policy所收集到的样本,采样效率较低。
使用基于策略的方法时,我们将直接优化所需的内容。 这样可以提高稳定性和可靠性。另一方面(基于价值的方法),Q学习方法是 通过基于目标函数估算Q值来间接实现的。有许多因素可能会使此类学习失败,因此,这些方法的稳定性较差。但是,这些算法的主要优点是采样效率更高,因为它们可以更有效地重用数据。在实际机器人上实施时,这一点尤其重要。
4、RL for manipulation
通常,在机器人技术方面,RL通常以高维动作和状态空间表示,对于机器人manipulation,收集数据通常是昂贵且费时的,且存在各种噪声,要收集单个训练样本,机器人可能需要几分钟才能移动或执行任务。机器人通常被建模为部分可观察的MDP, 因为状态不可观察或部分可观察。因此,成功的算法(尤其是基于模型的方法)需要对模型中的大量不确定性具有鲁棒性。在本节中,我们讨论三个主要问题,这些问题限制了RL在实际机器人问题中的应用。
A,sample inefficiency
采样效率低下是严重限制RL在机器人操作中的应用的主要原因之一。由于样本效率低下,即使是目前最好的一些RL算法也可能不切实际。有多种原因导致此问题,首先, 许多算法尝试从头开始学习执行任务,因此,它们需要大量数据来学习;其次,算法在利用当前数据中的有用信息方面仍然不够好;一些on-policy算法甚至在每个更新步骤都需要新数据。最后,机器人技术中的数据收集通常非常耗时。
(1)概览
进化算法的采样效率最低, 因为它们不使用梯度优化,但它们可能具有不错的性能。[8]中使用的进化策略用3-10倍的数据才能够在Atari游戏中匹配[9]中的性能。Actor-critic A3C [10]具有更高的数据效率, 能够超越 [9], 只需在多核CPU而非GPU上进行训练即可。Policy Gradient方法例如[11],具有高效的采样效率,接下来的方法有Deep Deterministic Policy Gradients (DDPG) [12] 和Normalized Advantage Functions (NAF) [13]。基于模型的算法在数据效率方面处于领先地位, 因为它们试图推出环境模型并使用该模型来训练策略, 而不是来自实际交互的数据。Guided Policy Search[14]是可以高效利用数据,因为它使用轨迹优化(trajectory optimization)来指导策略学习并避免不良的局部最优。目前的winner是基于模型的 “浅层”算法,例如学习控制的概率推理(PILCO)[15][16]。使用PILCO,只需要大约4分钟就可以学习一个复杂的任务,例如块堆叠任务,并且在使用知识迁移时,时间可以减少到90秒。
(2)未解决的问题

为了提高数据效率,我们需要收集 更多的数据并更有效地使用当前拥有的数据。获得更多数据的一种方法是使用多个机器人同时收集数据,如图3所示,真实数据也可以通过合成数据(可能来自模拟器)进行扩充,这种方法已在许多研究中采用[17]-[ 19]。在这种方法中,需要减少合成数据和真实机器人数据之间的差距,以便模拟数据可以使用。差距在[20]的grasp任务中得以量化, 因此差异在学习过程中也将最小化。[21]使用深度学习架构通过合成图像将模拟图像映射到真实图像。为了弥补现实差距,[18]使用progressive networks,通过迁移学习在新任务中从低级视觉功能重用到高级功能。我们还需要一种机制,来与许多有用的公共数据集共享数据。但是,在机器人技术中,数据用于特定的某些机器人和配置。如果我们有一种转换数据的机制,以使其可以广泛使用在多个平台和配置中。最后,我们将需要能够更有效地使用数据的新颖算法。基于模型的方法可能是提高数据利用效率的方法之一。
B,Exploration and exploitation
由于RL agent需要根据当前state和action不断采取行动, 因此根本问题是每次行动是进行exploration 还是exploitation。尽管探索提供了更多有关环境的知识,这可能会导致做出更好的决策。exploitation根据我们所拥有的当前信息选择了最优行动,将我们的范围缩小到当前最有希望的方向。最佳策略将涉及牺牲短期奖励以在将来获得更多奖励, 这意味着需要在Exploration 与exploitation之间取得平衡。
(1)概览
DQN[4]使用E-greedy [23] 平衡了Exploration 和exploitation。使用此策略, agent将以概率E采取随机行动,或以概率1-E采取使Q值最大化的action。还存在其他变体, 例如随着时间推移而衰减的E greedy 降低E以及自适应版本[24 ],它可以根据时间差调整E。Vanilla策略梯度法, (TRPO)[25]和(PPO) [26]通过根据随机策略的对操作进行采样来进行探索。DDPG[12]以离线的方式训练确定性策略,并在训练时将噪声添加到操作中。Soft Actor-Critic(SAC) [27]用熵正则化进行探索。其他探索方法包括adversarial self-play [28] 和parameter noise [29]。
(2)存在的问题
在诸如机器人技术之类的连续高维动作空间中寻找有效的探索方法仍然充满挑战。虽然E-greedy[24]是最常用的Exploration 方法之一,它有几个缺点。一个问题 是,它平等地对待所有动作(随机动作时)。因此,E-greedy策略是无指导性的,过于幼稚的,并且不会探索有前途的行动领域。对于按策略算法,随机性在很大程度上取决于初始条件和训练过程。在训练期间,由于更新策略规则有利于更多的exploitation, 随机性的规模减小了,结果,该策略可能会陷入局部最优状态。对于确定性策略,在训练期间将噪声添加到其操作中,并且可以减小噪声的规模以获取更多高质量的训练时间。当面对稀疏和欺骗性的奖励问题时,这种方法将变得不足。我们还缺乏可用于评估不同Exploration 方法性能的基准。而且,Exploration 策略的性能随环境和配置的不同而变化,因此很难量化出真正的改进。真正的机器人进行探索时的安全性是另一个问题。例如,对于脆弱的机器人来说,诸如面对不确定性进行探索之类的探索策略是非常不安全的。
C,Generalization and reproducibility
泛化是许多研究人员希望RL算法可以实现的关键基石。对于未来面对各种复杂现实环境的机器人,可以在各种环境中发挥作用。不幸的是,大多数RL算法都是使用针对特定任务或一小组任务的经过调整的超参数进行训练的,并且它们经常因新颖的任务或环境而失败。另一方面,在RL中,可重复性是一个被低估的问题,而且没有多少研究人员试图对此问题进行深入研究。要从许多最新的论文中复现结果并不容易,因为实现细节可能丢失或不完整。当加上RL算法当前遭受的不稳定性时,情况甚至更糟。
(1) 概览
目前有两个主要方向用于研究RL算法的泛化。第一种方法类似于设计策略时的控制理论中的鲁棒控制,以便通过消除其他环境中的性能来使它们仍然可以随着环境变化而起作用。在这个方向上,[30]学会了一种在环境分布中最大化风险条件值的策略,[31]在具有最低预期回报的环境子集中最大化了预期回报。
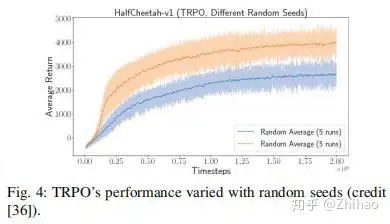
[32]使用对抗训练来学习强大的政策。第二种方法类似于自适应控制,试图适应当前的环境,例如[33]。许多算法[34] [35]使用从进行中的环境中采样的轨迹作为识别环境的机制,从而触发了策略的自主调整。关于RL的可重复性,深入探讨此问题的最佳论文之一是[36],其中分析了性能对许多因素的依赖性。网络结构是可能严重影响RL算法性能的因素之一,例如与TRPO和DDPG一样[37]。随机种子是另一个对性能有很大影响的因素。如果仅对少量随机种子进行测试,则报告的性能将不可靠。如图4所示,当TRPO在相同的超参数集上运行并且具有两个不同的随机种子时,两种情况下的性能差异显着。[36]还比较了许多其他因素的性能,例如环境,实施(代码库),奖励等级。对于所有测试的因素,性能差异很大。为了提高鲁棒性,一些研究试图通过视觉反馈来闭合控制回路[38],或者使用遗传算法来优化超参数[39]。
(2)存在的问题
我们目前没有有效的基准来评估RL算法的通用性。RL算法需要类似于在监督学习中使用的诸如ImageNet数据集的东西,以测试各种任务中的泛化能力。对于此类用于度量泛化的测试平台,我们还需要明确定义一组任务,比较指标和基线,以便我们可以公平地量化RL算法的泛化。为了量化RL算法中的泛化,OpenAI最近发布了CoinRun(图5),这是衡量泛化的初始基准。文献[40]中还显示,监督学习中常用的针对过度拟合的技术可以提高RL的通用性。通常,很难在机器学习中与可重复性相抗衡,并且由于不稳定性较高,对于连续环境(如机器人)在RL中更具挑战性。除了需要针对超参数的更鲁棒的RL算法外,我们可能还需要就正确的实验方法,正确的评估方法和度量标准达成共识。用于记录实验设置中的更改的有效工具也很有用于提高重现性。还必须有一套标准的环境,以便公平地验证可重复性。

5、未来方向
该领域未来发展的最大方向可能是如何有效地将深度强化学习算法带入现实世界,以解决实际应用。因此,我们需要知道如何解决现实世界中的问题。从我们的角度来看,机器人必须学习得更快,更有效。未来的研究领域具有广阔的潜力,包括基于模型的学习,从先前受过训练的任务中学习以及迁移学习和domain adaptation[41]。
基于模型的学习最大的优势是样本效率高,并且在这个方向上已有有趣的研究。在Atari游戏的背景下,[43]使用深度网络架构成功预测了未来100多个步骤。由于此方法是基于视觉的,因此有可能推广到其他视觉上丰富的RL问题。另一项研究[44]使用递归神经网络对未来数百个时间步进行时间和空间连贯的预测,以改善Atari和某些3D游戏的探索性。在机器人操纵的背景下,最近的一篇论文[45]引入了(SAVP)-(GAN)[46]和(VAE)[47]变体,尽管被训练来预测10个未来的帧,但仍可以预测数百个帧。在[48]中引入了另一个有趣的想法,将模型学习和计划集成在一起形成一个端到端的训练过程。此方法解决了估算的模型与实际模型不一致,从而导致规划性能不佳的问题。但是,在我们看来,这些最近的基于模型方法的研究才刚刚开始在丰富的环境中工作,并且还有很长的路要走。
对于当前的RL算法,从其他任务中学习的能力仍然非常困难。在学习新技能时,即使是最先进的RL算法与人类之间,在采样效率方面仍然存在很大差距。人类之所以更快地学习,可能是因为我们没有从头开始学习。相反,我们可以重用过去的知识来更有效地学习新技能。基于模型的学习方法由于具有更大的潜在可移植性和通用性,因此在这种情况下也可以提供帮助。环境模型可以重用于各种任务,这些任务可能受相同的物理定律支配。[49]使用中型神经网络来近似动力学,然后使用模型预测控制(MPC)来产生稳定的性能,以完成MuJoCo中各种复杂的运动任务[50]。在本文中,他们还通过使用基于模型的学习控制器将基于模型的方法与无模型方法相结合,以使用无模型学习生成用于微调的展开。这种结合可以加快学习速度,并提高3-5倍的采样效率。另一种方法不是近似动态,而是使用多任务学习来重用技能[51]。这项工作的有趣之处在于,与在单任务设置中学习相比,在各种任务上进行学习实际上具有更好的性能。通过对多个任务使用相同的大型神经网络,而不是对每个任务使用较小的网络,对于多个任务,性能显着提高。
迁移学习尝试利用之前任务中的经验来更快地学习并在新任务上获得更好的性能。从模拟器训练的任务中迁移学习非常诱人,因为只需要相对很少的资源。最近的另一种方法是使用domain adaptation来执行相关的Atari游戏之间的迁移学习[42]。它首先以actor-critic的方式在游戏中训练策略,然后在此域中转换状态表示,以初始化目标域的policy网络。这种方法大大提高了采样效率。[52]通过引入额外的奖励来使模拟和真实机器人之间并行学习,这些奖励激励两个域中的两个agent在状态上具有相似的分布。 inverse RL [53]也是一个有希望的未来方向,它可以解决设计合理奖励函数的麻烦。通过卷积神经网络自主学习的功能彻底改变了计算机视觉的世界。
[1] H. M. La, R. Lim, and W. Sheng, “Multirobot cooperative learning for predator avoidance,” IEEE Transactions on Control Systems Technology, vol. 23, no. 1, pp. 52–63, 2015.
[2] M. Rahimi, S. Gibb, Y. Shen, and H. M. La, “A comparison of various approaches to reinforcement learning algorithms for multi-robot box pushing,” in Intern. Conf. on Engineering Research and Applications.Springer, 2018, pp. 16–30.
[3] H. X. Pham, H. M. La, D. Feil-Seifer, and A. Nefifian, “Cooperative and distributed reinforcement learning of drones for fifield coverage,” 2018.[4] V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wier stra, and M. Riedmiller, “Playing atari with deep reinforcement learning,” in NIPS Deep Learning Workshop, 2013.
[5] D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, A. Huang,A. Guez, T. Hubert, L. Baker, M. Lai, A. Bolton et al., “Mastering the game of go without human knowledge,” Nature, vol. 550, no. 7676, p. 354, 2017.
[6] J. Kober, J. A. Bagnell, and J. Peters, “Reinforcement learning in robotics: A survey,” The Intern. J. of Robotics Research, vol. 32, no. 11, pp. 1238–1274, 2013.
[7] R. S. Sutton and A. G. Barto, Reinforcement learning: An introduction. MIT press, 2018.
[8] T. Salimans, J. Ho, X. Chen, S. Sidor, and I. Sutskever, “Evolution strategies as a scalable alternative to reinforcement learning,” arXiv preprint arXiv:1703.03864, 2017.
[9] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski et al., “Human-level control through deep reinforcement learning,” Nature, vol. 518, no. 7540, p. 529, 2015.
[10] V. Mnih, A. P. Badia, M. Mirza, A. Graves, T. Lillicrap, T. Harley, D. Silver, and K. Kavukcuoglu, “Asynchronous methods for deep reinforcement learning,” in Intern. Conf. on Machine Learning, 2016, pp. 1928–1937.
[11] J. Schulman, S. Levine, P. Abbeel, M. Jordan, and P. Moritz, “Trust region policy optimization,” in Intern. Conf. on Machine Learning, 2015, pp. 1889–1897.
[12] T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa, D. Silver, and D. Wierstra, “Continuous control with deep reinforcement learning,” arXiv preprint arXiv:1509.02971, 2015.
[13] S. Gu, T. Lillicrap, I. Sutskever, and S. Levine, “Continuous deep q learning with model-based acceleration,” in Intern. Conf. on Machine Learning, 2016, pp. 2829–2838.
[14] S. Levine and V. Koltun, “Guided policy search,” in Intern. Conf. on Machine Learning, 2013, pp. 1–9.
[15] M. Deisenroth and C. Edward Rasmussen, “Pilco: A model-based and data-effificient approach to policy search.” 01 2011, pp. 465–472.
[16] M. P. Deisenroth, C. E. Rasmussen, and D. Fox, “Learning to control a low-cost manipulator using data-effificient reinforcement learning,” in Robotics: Science and Systems, 2011.
[17] J. Tan, T. Zhang, E. Coumans, A. Iscen, Y. Bai, D. Hafner, S. Bohez, and V. Vanhoucke, “Learning to control a low-cost manipulator using data-effificient reinforcement learning,” in Robotics: Science and Systems, 2018.
[18] A. A. Rusu, M. Vecerik, T. Rothorl, N. Heess, R. Pascanu, and R. Hadsell, “Sim-to-real robot learning from pixels with progressive nets,” arXiv preprint arXiv:1610.04286, 2016.
[19] X. B. Peng, M. Andrychowicz, W. Zaremba, and P. Abbeel, “Sim-to-real transfer of robotic control with dynamics randomization,” in 2018 IEEE Intern. Conf. on Robotics and Automation (ICRA). IEEE, 2018, pp. 1–8.
[20] U. Viereck, A. t. Pas, K. Saenko, and R. Platt, “Learning a visuomotor controller for real world robotic grasping using simulated depth images,”arXiv preprint arXiv:1706.04652, 2017.
[21] E. Tzeng, C. Devin, J. Hoffman, C. Finn, X. Peng, S. Levine, K. Saenko, and T. Darrell, “Towards adapting deep visuomotor representations from simulated to real environments,” CoRR, abs/1511.07111, 2015.
[22] S. Levine, P. Pastor, A. Krizhevsky, J. Ibarz, and D. Quillen, “Learning hand-eye coordination for robotic grasping with deep learning and large scale data collection,” The Intern. J. of Robotics Research, vol. 37, no. 4-5, pp. 421–436, 2018.
[23] C. J. C. H. Watkins, “Learning from delayed rewards,” Ph.D. dissertation, King’s College, Cambridge, 1989.
[24] M. Tokic, “Adaptive ε-greedy exploration in reinforcement learning based on value differences,” in Annual Conf. on Artifificial Intelligence Springer, 2010, pp. 203–210.
[25] J. Schulman, S. Levine, P. Abbeel, M. Jordan, and P. Moritz, “Trust region policy optimization,” in Intern. Conf. on Machine Learning, 2015, pp. 1889–1897.
[26] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv preprint arXiv:1707.06347, 2017.
[27] T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off policy maximum entropy deep reinforcement learning with a stochastic actor,” arXiv preprint arXiv:1801.01290, 2018.
[28] S. Sukhbaatar, Z. Lin, I. Kostrikov, G. Synnaeve, A. Szlam, and R. Fergus, “Intrinsic motivation and automatic curricula via asymmetric self-play,” arXiv preprint arXiv:1703.05407, 2017.
[29] M. Plappert, R. Houthooft, P. Dhariwal, S. Sidor, R. Y. Chen, X. Chen, T. Asfour, P. Abbeel, and M. Andrychowicz, “Parameter space noise for exploration,” arXiv preprint arXiv:1706.01905, 2017.
[30] A. Tamar, Y. Glassner, and S. Mannor, “Optimizing the cvar via sampling.” in AAAI, 2015, pp. 2993–2999.
[31] A. Rajeswaran, K. Lowrey, E. V. Todorov, and S. M. Kakade, “Towards generalization and simplicity in continuous control,” in Advances in Neural Information Processing Systems, 2017, pp. 6550–6561.
[32] L. Pinto, J. Davidson, R. Sukthankar, and A. Gupta, “Robust adversarial reinforcement learning,” arXiv preprint arXiv:1703.02702, 2017.
[33] W. Yu, J. Tan, C. K. Liu, and G. Turk, “Preparing for the unknown: Learning a universal policy with online system identifification,” arXiv preprint arXiv:1702.02453, 2017.
[34] N. Mishra, M. Rohaninejad, X. Chen, and P. Abbeel, “Meta-learning with temporal convolutions,” arXiv preprint arXiv:1707.03141, 2017.
[35] F. Sung, L. Zhang, T. Xiang, T. Hospedales, and Y. Yang, “Learning to learn: Meta-critic networks for sample effificient learning,” arXiv preprint arXiv:1706.09529, 2017.
[36] P. Henderson, R. Islam, P. Bachman, J. Pineau, D. Precup, and D. Meger, “Deep reinforcement learning that matters,” arXiv preprint arXiv:1709.06560, 2017.
[37] R. Islam, P. Henderson, M. Gomrokchi, and D. Precup, “Reproducibility of benchmarked deep reinforcement learning tasks for continuous control,” arXiv preprint arXiv:1708.04133, 2017.
[38] H. Nguyen, H. M. La, and M. Deans, “Deep learning with experience ranking convolutional neural network for robot manipulator,” arXiv preprint arXiv:1809.05819, 2018.
[39] A. Sehgal, H. M. La, S. J. Louis, and H. Nguyen, “Deep reinforcement learning using genetic algorithm for parameter optimization,” Submitted for Intern. Conf. on Robotic Computing (IRC), 2019.
[40] K. Cobbe, O. Klimov, C. Hesse, T. Kim, and J. Schulman, “Quantifying generalization in reinforcement learning,” arXiv preprint arXiv:1812.02341, 2018.
[41] H.-J. Ye, X.-R. Sheng, D.-C. Zhan, and P. He, “Distance metric facil itated transportation between heterogeneous domains.” in IJCAI, 2018, pp. 3012–3018.
[42] T. Carr, M. Chli, and G. Vogiatzis, “Domain adaptation for reinforcement learning on the atari,” arXiv preprint arXiv:1812.07452, 2018.
[43] J. Oh, X. Guo, H. Lee, R. L. Lewis, and S. Singh, “Action-conditional video prediction using deep networks in atari games,” in Advances in neural information processing systems, 2015, pp. 2863–2871.
[44] S. Chiappa, S. Racaniere, D. Wierstra, and S. Mohamed, “Recurrent environment simulators,” arXiv preprint arXiv:1704.02254, 2017.
[45] A. X. Lee, R. Zhang, F. Ebert, P. Abbeel, C. Finn, and S. Levine, “Stochastic adversarial video prediction,” arXiv preprint arXiv:1804.01523, 2018.
[46] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” in Advances in neural information processing systems, 2014, pp. 2672– 2680.
[47] D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” arXiv preprint arXiv:1312.6114, 2013.
[48] D. Silver, H. van Hasselt, M. Hessel, T. Schaul, A. Guez, T. Harley, G. Dulac-Arnold, D. Reichert, N. Rabinowitz, A. Barreto et al., “The predictron: End-to-end learning and planning,” arXiv preprint arXiv:1612.08810, 2016.
[49] A. Nagabandi, G. Kahn, R. S. Fearing, and S. Levine, “Neural network dynamics for model-based deep reinforcement learning with model-freefifine-tuning,” in 2018 IEEE Intern. Conf. on Robotics and Automation(ICRA). IEEE, 2018, pp. 7559–7566.
[50] E. Todorov, T. Erez, and Y. Tassa, “Mujoco: A physics engine for model based control,” in Intelligent Robots and Systems (IROS), 2012 IEEE/RSJ Intern. Conf. on. IEEE, 2012, pp. 5026–5033.
[51] R. Rahmatizadeh, P. Abolghasemi, L. Bol oni, and S. Levine, “Vision-based multi-task manipulation for inexpensive robots using end-to-end learning from demonstration,” in 2018 IEEE Intern. Conf. on Robotics and Automation (ICRA). IEEE, 2018, pp. 3758–3765.
[52] M. Wulfmeier, I. Posner, and P. Abbeel, “Mutual alignment transfer learning,” arXiv preprint arXiv:1707.07907, 2017.
[53] A. Y. Ng, S. J. Russell et al., “Algorithms for inverse reinforcement learning.” in ICML, 2000, pp. 663–670.