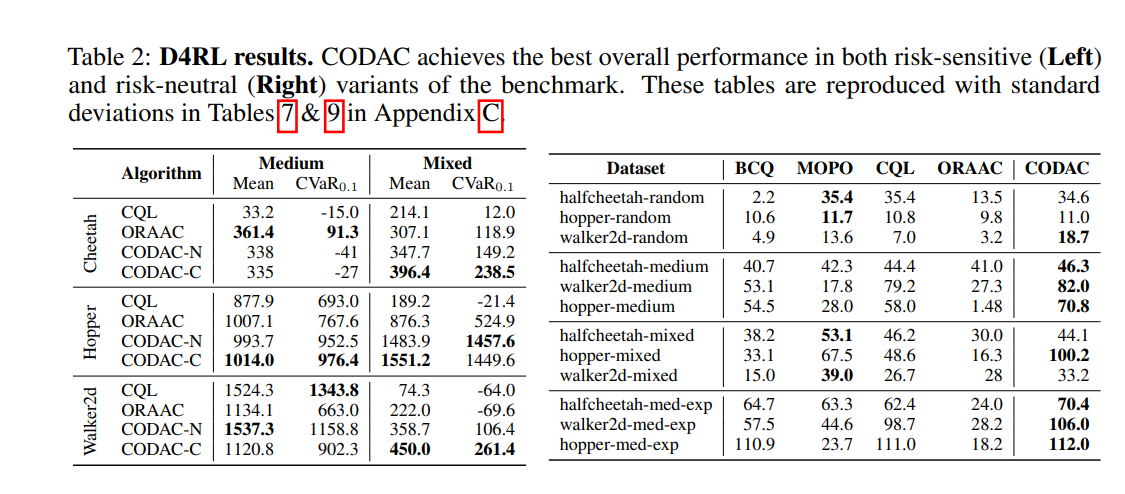
实践中的许多强化学习(RL)问题都是离线的,纯粹从观察数据中学习。一个关键挑战是如何确保学到的策略是安全的,这需要量化与不同行动相关的风险。在在线环境中,分布式RL算法通过学习回报(即累积回报)的分布而不是预期回报来实现;除了量化风险之外,他们还被证明能够更好地学习规划表达。我们提出了一种适用于风险中性和风险规避领域的离线RL算法——保守离线分配行为批评(CODAC)。CODAC通过惩罚分布外行为的预测分位数,使分布RL适应离线设置。我们证明了CODAC学习保守的回报分布——特别是,对于有限的MDP,CODAC收敛于回报分布的分位数上的一致下界;我们的证明依赖于对分布Bellman算子的新分析。在我们的实验中,在两个具有挑战性的机器人导航任务中,CODAC使用纯从风险中性代理收集的离线数据成功地学习了风险规避策略。此外,CODAC在D4RL MuJoCo基准测试中的预期性能和风险敏感性能都是最先进的。

在强化学习的许多应用中,通过与环境的交互来主动收集数据可能是危险和不安全的。离线(或批量)强化学习(RL)通过仅从历史数据(称为观测数据)学习策略来避免这个问题[9,22,23]。大多数现有的离线RL[11,46,20,21,48,18]方法的一个缺点是,它们旨在最大化政策的累积奖励(我们称之为回报)的预期值。因此,他们无法量化风险并确保所学政策以安全的方式实施。在在线环境中,最近有关于分布式RL算法的研究[7,6,27,38,17],这些算法学习未来收益的完全分布。他们可以使用这种分布来避免采取危险、不安全的行动。此外,当与深度神经网络函数近似相结合时,由于更丰富的分布学习信号,他们可以学习更好的状态表示[4,26],使他们即使在风险中性的预期回报目标[4,7,6,47,14]上也能优于传统的RL算法。我们提出了保守的离线分发演员评论家(CODAC),它使分发RL适应离线环境。离线RL中的一个关键挑战是解释观测数据有限的分布外(OOD)状态动作对的高度不确定性[23,20];这些状态-动作对的值估计本质上是高方差的,并且由于缺乏在线数据收集和反馈,可能会被策略利用而不进行校正。我们基于保守的Q学习[21],它惩罚OOD状态动作对的Q值,以确保学习的Q函数低于真实的Q函数。类似地,CODAC使用惩罚来确保学习的回报分布的分位数低于真实回报分布的分数位数。关键的是,下限是数据驱动的,并选择性地惩罚离线数据集中不太频繁的状态行为的分位数估计;见图1。图1:CODAC获得真实返回分位数的保守估计(黑色);它惩罚分布外行为µ(a|s),比不分布行为更严重,⇡ˆ(a | s)。我们证明了对于有限MDP,CODAC收敛于返回分布的估计,其分位数一致下界为真实返回分布的分位数;此外,在使用有限数据估计分位数时,这个数据驱动的下限紧到近似误差。因此,CODAC获得了所有分位数积分的统一下限,包括预期收益的标准RL目标、风险敏感条件风险值(CVaR)目标[35]以及许多其他风险敏感目标。我们还证明,CODAC扩大了分布和OOD行为之间的分位数估计差距,从而避免了外推到OOD行为时的过度自信[11]。