依靠太多的实验来学习好的动作,当前的强化学习(RL)算法在现实世界中的适用性有限,这可能太昂贵,无法进行探索。我们提出了一种用于批量RL的算法,其中仅使用固定的离线数据集而不是与环境的在线交互来学习有效的策略。批量RL中的有限数据在训练数据中未充分表示的状态/动作的值估计中产生固有的不确定性。当我们的候选政策与生成数据的政策不同时,这会导致特别严重的外推。我们建议通过两种直接的惩罚来缓解这个问题:一种是减少这种分歧的政策约束,另一种是阻止过度乐观估计的价值约束。在一组全面的32个连续动作批量RL基准测试中,无论离线数据是如何收集的,我们的方法都优于最先进的方法。

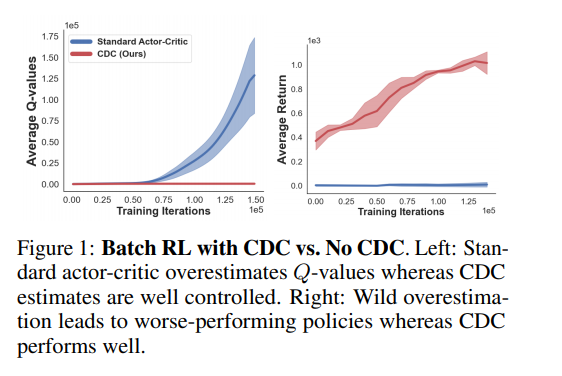
深度RL算法在视频游戏等可模拟数字环境中表现出令人印象深刻的性能[41,54,55]。在这些设置中,智能体可以执行不同的策略并观察其性能。除非有几个例子[37],进步并没有很好地转化为现实环境,在现实环境中,经历数百万次环境交互通常是不可行的[11]。此外,在存在可接受的启发式算法的情况下,部署一个从头开始学习的智能体,希望在经过充分的实验后,它最终可能会优于启发式算法,这是不合适的。相反,批量或离线RL的设置提供了一个更相关的框架来学习现实应用程序的性能策略[34,57]。Batch RL广泛适用,因为此设置不要求:通过真实环境交互测试建议的策略,或根据特定策略收集数据。相反,智能体只能访问通过根据某个未知行为策略πb采取的操作收集的固定数据集D。此设置中的主要挑战是数据可能仅跨越可能的状态-动作对的一小部分。更糟糕的是,智能体无法观察到D中定义不存在的新的分布外(OOD)状态-动作组合的影响。一个关键挑战源于从有限数据中学习时的固有不确定性[28,36]。未能解释这一点可能会导致粗暴的推断[17,29]和价值估计中的过度/低估偏差[22,23,32,58]。这是一个系统性问题,在数据稀缺的情况下,这一问题会因分发外(OOD)状态行为而加剧。Q值的标准时间差更新依赖于Bellman最优算子,这意味着向上外推估计往往主导这些更新。随着Q值随着高估目标的更新,即使是在D中很好地表示的状态动作,它们也会向上偏移。反过来,这会进一步增加OOD状态动作的外推误差上限,这会形成图1所示的外推过度高估(简称超高估)的恶性循环。这种额外的高估比在线RL中常见的高估偏差严重得多[22,58]。因此,我们迫切需要在价值估计导致潜在“太好而不真实”的情况时限制价值估计,尤其是在发生政策可能利用价值估计的情况时。同样,幼稚的探索可能导致政策与πb显著不同。这反过来导致了更大的估计误差,因为我们在这个未经探索的空间中只有很少的数据。请注意,这并不是在线RL中特别关注的原因:毕竟,一旦我们完成了对空间中某一区域的探索,结果发现该区域的前景不如我们想象的那么好,我们只需更新价值函数,停止访问或很少访问。在批量RL中情况并非如此,因为我们无法根据观察其在环境中的实际影响来调整我们的策略。对于具有大量可能状态和操作的应用程序,例如本工作中考虑的连续设置,这些问题会加剧。由于没有机会在批量RL中试用建议的策略,因此学习必须保持适当的保守,以便在稍后实际部署时该策略具有合理的效果。标准正则化技术在监督学习中被用来解决这种不明确的估计问题,并且也被用于RL设置[12,50,62]。本文通过添加一对简单的正则化器,使标准的非策略行为体批评者RL适应批量设置。特别是,我们的主要贡献是引入了两个新的批量RL正则化器:第一个正则化器消除了分布外区域的额外高估偏差。第二个正则化器旨在对冲政策更新的不利影响,这些政策更新严重偏离πb(a|s)。所得方法连续双约束批量RL(CDC)在D4RL基准[14]的32个连续控制任务中表现出最先进的性能,证明了我们的正则化器对批量RL的有用性。