在本文中,我们提出了一种用于强化学习(RL)的最大-最小熵框架,以克服软行为批评(SAC)算法在基于模型的无样本学习中实现最大熵RL的局限性。尽管最大熵RL指导学习策略以在未来达到具有高熵的状态,但所提出的最大最小熵框架旨在学习访问具有低熵的状态并最大化这些低熵状态的熵,以促进更好的探索。对于一般马尔可夫决策过程(MDP),基于探索和开发的分离,在所提出的最大最小熵框架下构造了一种有效的算法。数值结果表明,与当前最先进的RL算法相比,所提出的算法产生了显著的性能改进。


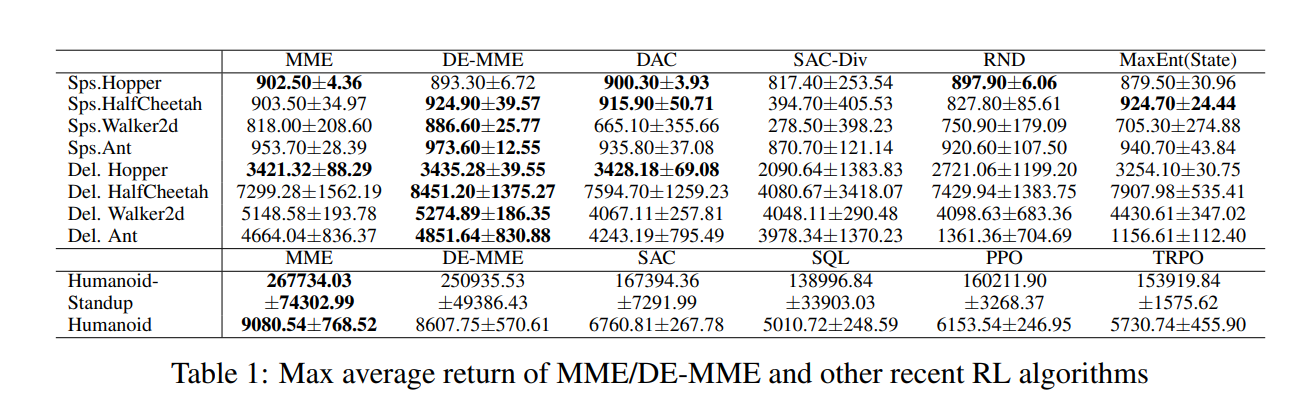
在各种RL域[22,23,30,45,51,53,58]中考虑了最大熵框架。最大熵RL将期望的策略熵添加到标准RL的返回目标,以便最大化策略分布的返回和熵。最大熵RL鼓励策略以概率方式选择多个动作,并在各种控制任务中产生探索性和鲁棒性的显著改进以及良好的最终性能[15,20,21,25,26,29,50]。特别是,软角色批评者(SAC)以基于软策略迭代的高效迭代方式实现最大熵RL,并保证收敛到有限MDP的最优策略,在许多连续控制任务中,与各种策略上和策略外的最近RL算法相比,产生了显著的性能改进。然而,我们观察到,对于旨在在未来达到具有高熵的状态的策略进行优化的最大熵策略的这种迭代实现不一定会导致期望的探索行为,但可能会产生正反馈,从而阻碍具有函数近似的无模型样本学习中的探索。为了克服与最大熵RL的实现相关联的这些限制,我们提出了RL的最大-最小熵框架,该框架旨在学习到达具有低熵的状态的策略并最大化这些低熵状态的熵,而传统的最大熵RL针对旨在访问具有高熵的状态的策略进行优化,并针对整个轨迹的高熵使那些高熵状态的熵最大化。我们将所提出的最大-最小熵框架实现为一种实用的迭代演员-评论家算法,该算法基于策略迭代,具有不纠缠的探索和开发。证明了所提出的算法由于max-min框架引起的跨状态的公平性而显著增强了探索能力,并在困难的控制任务上产生了比现有RL算法(包括最大熵SAC)更大的性能改进。