反向强化学习解决了从演示中推断专家奖励函数的问题。然而,在许多应用程序中,我们不仅可以访问专家近乎最佳的行为,而且还可以观察她的学习过程的一部分。在本文中,我们针对这一设置提出了一种新的算法,其中的目标是恢复由智能体优化的奖励函数,给定学习过程中产生的一系列策略。我们的方法基于这样的假设,即被观察的智能体正在沿着梯度方向更新其策略参数。然后,我们扩展了我们的方法,以处理更现实的场景,其中我们只能访问学习轨迹的数据集。对于这两种设置,我们都提供了算法性能的理论见解。最后,我们在模拟GridWorld环境和MuJoCo环境中评估了该方法,并将其与最先进的基线进行了比较。

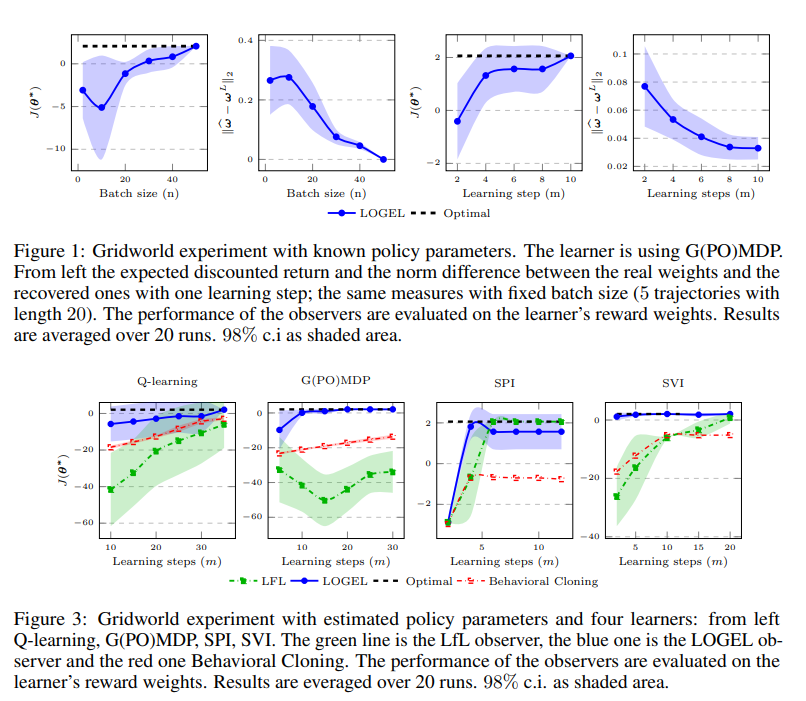
反向强化学习(IRL)[20]旨在从专家的演示中推断其奖励功能[21]。在标准设置中,专家通过与环境反复互动来表现行为。这种行为由其政策编码,正在优化未知的奖励功能。IRL的目标包括找到一个使专家行为最优的奖励函数[20]。与输出模仿策略(如行为克隆[3])的其他模仿学习方法[3],15]相比,IRL明确地提供了专家意图的简洁表示。因此,它概括了专家对未观察到的情况的政策。然而,在某些情况下,不可能等待示威者学习过程的收敛。例如,在多智能体环境中,一个智能体在真正成为“专家”之前,必须推断出其他智能体正在学习的未知奖励函数;这样她就可以与他们合作或竞争。另一方面,在许多情况下,我们可以通过观察代理的学习过程来学习一些有用的东西。这些观察结果包含有关代理人意图的重要信息,可用于推断其兴趣。想象一个正在学习新电路的驾驶员。在她的训练中,我们可以观察她在各种情况下(甚至是危险的情况下)的表现,这有助于了解哪些状态是好的,哪些状态应该避免。相反,当观察到专家行为时,只能探索国家空间的一小部分区域,从而使观察者不知道在专家政策下不太可能发生的情况下该怎么办。Jacq等人最近在[17]中提出了非专家代理的反向强化学习,称为学习者学习(LfL)。LfL涉及两个主体:一个正在学习任务的学习者和一个想要推断学习者意图的观察者。在[17]中,作者假设学习者在熵正则化框架下学习,其动机是假设学习者表现出一系列不断改进的政策。然而,许多强化学习(RL)算法[35]不满足这一点,而且人类学习的特点是可能导致非单调学习过程的错误。在本文中,我们提出了一种新的LfL设置算法,称为学习观察梯度非专家学习者(LOGEL),该算法不受违反不断改进假设的影响。鉴于许多成功的RL算法都是基于梯度的[22],并且有一些证据表明人类学习过程类似于基于梯度的方法[32],我们假设学习者遵循其预期折扣回报的梯度方向。该算法学习奖励函数,该奖励函数最小化学习者的实际策略参数与如果她使用该奖励函数遵循策略梯度应获得的策略参数之间的距离。在第3节中正式介绍了LfL设置之后,我们在第4节中提供了当观察者可以完全访问学习者的策略参数和学习率时LfL问题的第一个解决方案。然后,在第5节中,我们将算法扩展到更现实的情况,在这种情况下,观察者只能通过分析学习者的轨迹来识别优化的奖励函数。对于每个问题设置,我们都提供了有限样本分析,以使读者直观地了解恢复权重的正确性。最后,我们考虑离散和连续模拟域,以经验方式将所提出的算法与该设置中的最新基线进行比较[17,7]。附录A中报告了所有结果的证明。在附录中,我们报告了模拟自动驾驶任务B.3的初步结果。