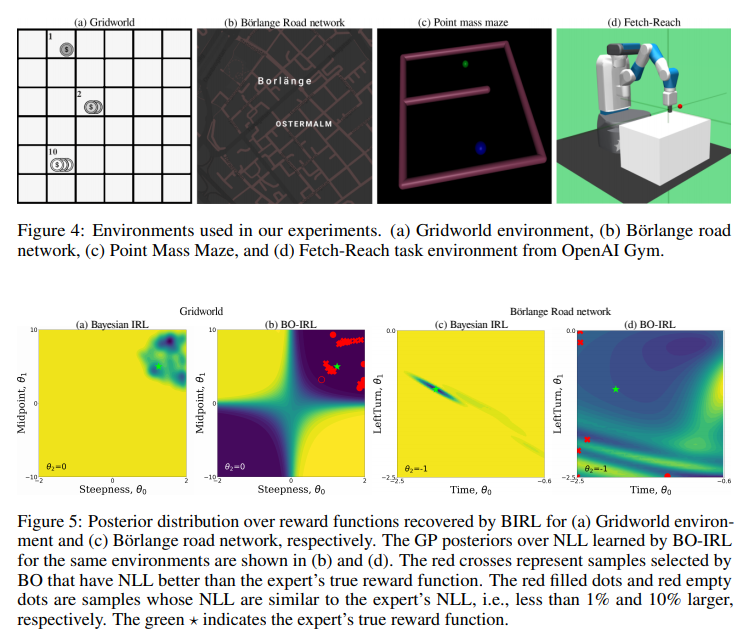
逆强化学习(IRL)问题与各种任务相关,包括价值取向和机器人演示学习。尽管近年来在算法上做出了重大贡献,IRL仍然是一个核心问题;多个奖励函数与观察到的行为一致,并且在没有先验知识或补充信息的情况下,实际的奖励函数是不可识别的。本文提出了一种称为贝叶斯优化IRL(BO-IRL)的IRL框架,该框架通过有效探索奖励函数空间来识别与专家演示一致的多个解决方案。BO-IRL通过利用贝叶斯优化以及我们新提出的核来实现这一点,该核(a)将策略不变奖励函数的参数投影到潜在空间中的单个点,并且(b)确保潜在空间中附近的点对应于产生相似似然度的奖励函数。这种投影允许使用潜在空间中的标准平稳核来捕获奖励函数空间中存在的相关性。在合成和现实环境(无模型和基于模型)上的经验结果表明,BO-IRL发现了多个奖励函数,同时最小化了昂贵的精确策略优化的数量。

反向强化学习(IRL)是从强化学习(RL)主体的观察行为推断其奖励函数的问题[1]。尽管应用广泛(例如[1,4,5,27]),IRL仍然是一个具有挑战性的问题。一个关键的困难是IRL是病态的;通常,存在许多解决方案(奖励函数),其中给定的行为是最优的[2,3,29],并且不可能在没有附加信息的情况下从这些备选方案中推断出真实的奖励函数,例如先验知识或更具信息性的演示[9,15]。鉴于IRL的不适定性,我们采用这样的观点:IRL算法应该表征解的空间,而不是输出单个答案。事实上,通常没有一个正确的解决方案。尽管该方法不同于传统的基于梯度的IRL方法[38]和收敛于奖励函数空间中的特定解的现代深度化身(例如,[12,14]),但它并非完全非常规。先前的方法,特别是贝叶斯IRL(BIRL)[32],分享了这一观点,并返回了可能的奖励函数的后验分布。然而,BIRL和其他类似方法[25]的计算成本很高(通常是由于精确的策略优化步骤),或者存在过拟合等问题[8]。