我们介绍了CuLE(CUDA学习环境),这是Atari学习环境(ALE)的CUDA端口,用于开发深度强化算法。CuLE克服了现有基于CPU的仿真器的许多限制,可以自然扩展到多个GPU。它利用GPU并行化同时运行数千个游戏,并直接在GPU上渲染帧,以避免因CPU-GPU通信带宽有限而产生的瓶颈。CuLE在单个GPU上每小时最多生成155M帧,这一发现以前仅通过CPU集群实现。除了强调强化学习背景下CPU和GPU仿真器之间的差异之外,我们还展示了如何通过有效批处理训练数据来利用CuLE的高吞吐量,并展示了A2C+V-trace的加速收敛。

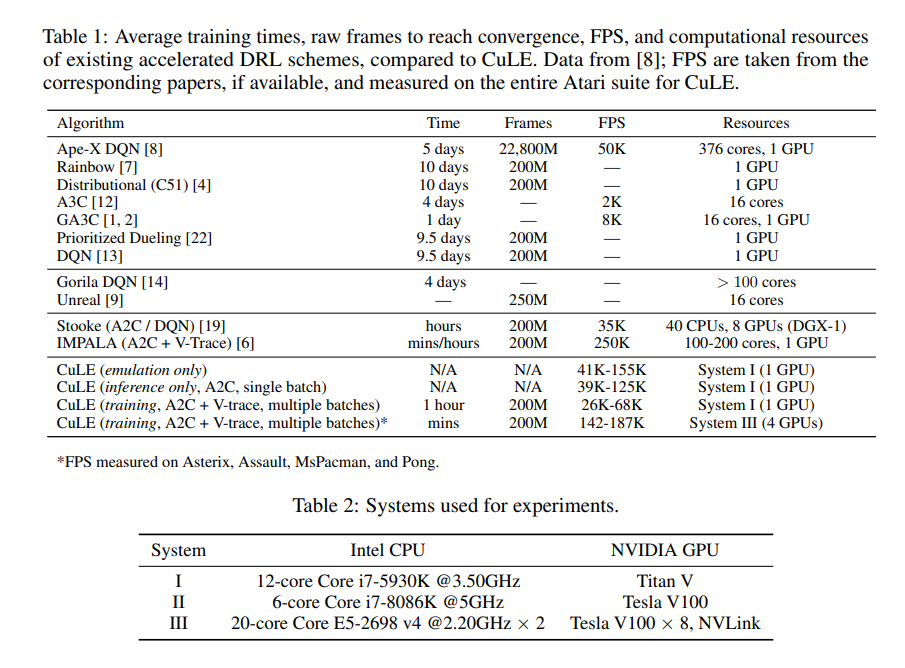
最初由DQN的成功引发[13],在过去几年中,深度强化学习(DRL)的研究越来越受欢迎[10,12,13],导致了在复杂环境中解决非琐碎任务的智能代理。但DRL也很快被证明是一个具有挑战性的计算问题,特别是如果人们想在现代架构上实现最高性能。传统的DRL培训侧重于执行一组操作的CPU环境−1} 在时间t− 1,并产生可观察状态{st}和奖励{rt}。然后,GPU上的深度神经网络(DNN)处理环境数据,以选择下一个操作,{at},并将其复制回CPU。这一操作序列定义了推理路径,其主要目的是生成训练数据。GPU上的训练缓冲器存储在推理路径上生成的状态;这被周期性地用于根据DRL算法的训练规则(训练路径)更新DNN的权重θ。一个计算效率高的DRL系统应该平衡数据生成和训练过程,同时最小化沿推理路径的通信开销,并沿训练路径每秒消耗尽可能多的数据[1,2]。然而,这个问题的解决方案并非微不足道,许多DRL实现没有充分利用现代系统的计算潜力[19]。我们将注意力集中在推理路径上,并从雅达利学习环境(ALE)的传统CPU实现转移,这是一套雅达利2600游戏,成为了一个出色的DRL基准[3,11]。我们表明,由于CPU无法同时运行一组大型环境,并且CPU-GPU通信带宽有限,因此基于CPU的环境仿真造成了严重的性能瓶颈。为了调查和缓解这些限制,我们引入了CuLE(CUDA学习环境),这是一个包含支持CUDA的Atari 2600仿真器的DRL库,该仿真器直接在GPU内存中渲染帧,避免了芯片外通信,并通过并行处理数千个环境来实现高GPU利用率,这是迄今为止只有通过大型且昂贵的分布式系统才能实现的。与传统的基于CPU的方法相比,GPU仿真提高了计算资源的利用率:与CPU(12.5K和19.8K之间)相比,单个GPU上的CuLE在推理路径上(39K和125K之间,取决于游戏,见表1)生成的每秒帧数2(FPS)更多。CuLE的吞吐量与更大的分布式系统(如IMPALA[6]或DGX-1[20])具有相同的数量级,这最终导致挂钟训练时间的显著减少,从而为该领域的研究人员带来了直接的实际优势[18,21,5]。除了提供CuLE(https://github.com/NVlabs/cule)作为DRL领域的研究工具,我们的贡献可以总结如下:(1)我们确定了几种DRL实现中的常见计算瓶颈,这些瓶颈阻碍了高吞吐量计算单元的有效利用和分布式系统的有效扩展。(2) 我们为大型环境集引入了一种有效的批处理策略,该策略允许利用CuLE生成的高吞吐量快速实现与A2C+V-trace[6]的收敛,并在多个GPU上显示出有效的扩展。这导致在单个GPU上沿训练路径消耗26-68K FPS,使用四个GPU时消耗高达187K FPS(表1),与大型集群实现的消耗相当[20,6]。(3) 我们分析了在DRL中使用CuLE进行GPU仿真的优势和局限性,包括线程发散的影响以及每个线程每秒指令数(与CPU相比)较低的影响,并希望我们的见解对开发高效的DRL系统有价值。