基于模型的离线强化学习(RL)由于其样本效率和可推广性,在许多决策问题中取得了优于无模型RL的性能。然而,文献中基于模型的离线RL方法要么仅通过实证研究证明其成功,要么提供具有理论保证但难以在实践中实现的算法。到目前为止,仍缺乏一种具有PAC保证的基于模型的离线RL的通用计算可处理算法。为了填补这一空白,我们开发了一种基于悲观模型的演员-评论家(PeMACO)算法,该算法采用假设离线数据集部分覆盖的一般函数近似。具体地说,评论家通过结合学习到的过渡模型的不确定性来提供悲观Q函数,参与者通过使用悲观Q函数的近似值来更新策略。在一些温和的假设下,我们通过证明PeMACO返回的策略的次优上界,建立了所提出的PeMACO算法的理论PAC保证。

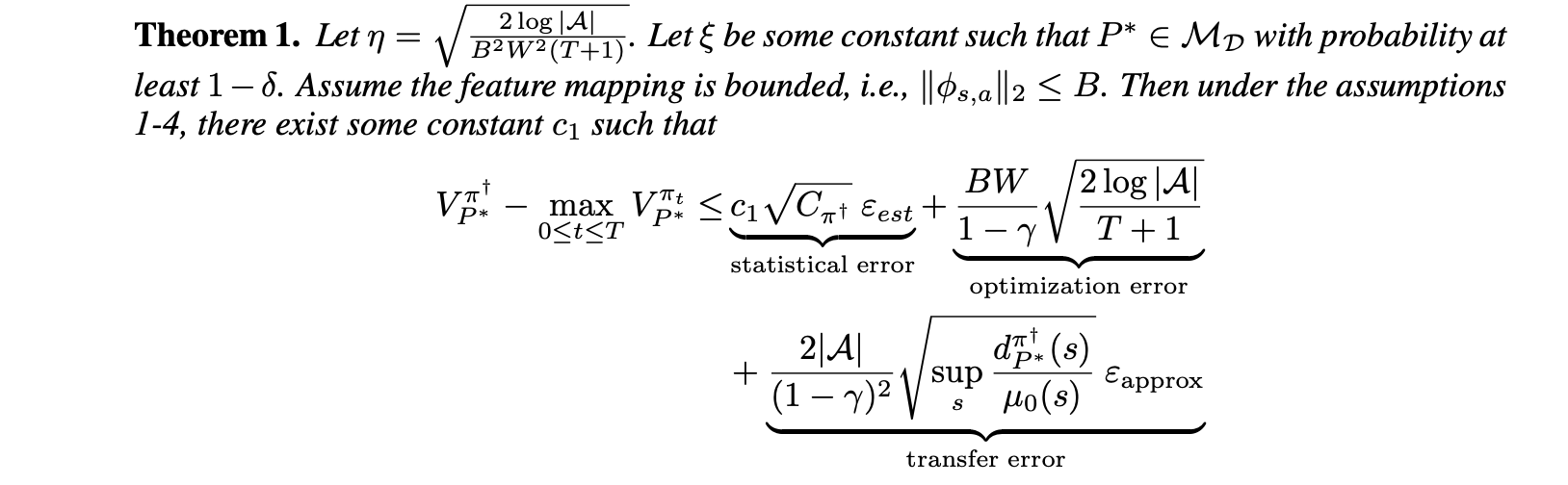

强化学习(RL)已经成为一种通过最大化学习最优策略的预期累积奖励来优化顺序决策的有效方法。RL算法在自动驾驶(Shalev Shwartz等人,2016)、视频游戏(Torrado等人,2018)和机器人技术(Kober等人,2013)等广泛领域取得了重大进展。然而,将RL应用于一些现实问题可能需要从预先收集的和静态(即离线)数据集中优化顺序决策,因为与环境交互可能是昂贵的或不道德的,例如在医疗保健应用中将患者分配给劣质或有毒的治疗(Gottesman等人,2019)。因此,近几十年来,开发离线RL方法迅速发展,以在不与环境进一步交互的情况下从离线数据集学习最优策略(Wu等人,2019;Kumar等人,2020;Kidambi等人,2020年;Yu等人,2020,Levine等人,2020)。离线RL方法的性能通常取决于离线数据的覆盖率。早期的离线RL理论研究通常假设离线数据具有全覆盖,即每个可能策略的状态分布都可以被生成离线数据的行为策略的分布所覆盖(Munos&Szepesvari,2008;Ross&Bagnell,2012;Uehara等,2020;Xie&Jiang,2021)。为了放松这一限制性假设,最近开发了许多无模型离线RL方法,通过合并悲观主义来考虑离线数据的部分覆盖(Liu等人,2020;Xie等人,2021;Zanette等人,2021)。然而,大多数现有的无模型方法需要Bellman完备性假设,这在实践中特别强,因为Bellman完全性缺乏单调性。相比之下,基于模型的离线RL方法越来越受到关注,因为理论上的假设更少,实践中的样本效率更好。Yu等人(2020)和Kidambi等人(2020年)通过修改从离线数据学习的马尔可夫决策过程(MDP)模型,并在过渡模型的不确定性方面引入悲观主义,提出了基于模型的离线RL方法。尽管他们在经验上取得了成功,但他们的工作中存在的不确定性并没有以准确的方式进行分析量化。例如,Yu等人。(2020)是过渡模型的逐点估计误差的上界,该误差未通过有限样本分析进行理论研究。最近,Uehara和Sun(2021)开发了一种基于一般函数近似的悲观模型离线算法,并证明了在部分覆盖和PAC(可能近似正确)保证下的次优差距的上界。然而,他们的算法在实践中不容易实现。受Uehara和Sun(2021)的启发,Rigter等人(2022)通过将最大-最小约束优化问题重新表述为对抗性环境模型的两人零和博弈,设计了一种计算可处理的算法。然而,他们算法的理论性质尚未得到研究。一个挑战仍然存在:我们能否设计一个基于模型的离线RL算法,不仅可以在实践中实现,而且具有PAC保证?在这项工作中,我们通过提出PeMACO来填补这一空白,PeMACO是一种用于离线RL的基于悲观模型的演员-评论家(AC)算法。在AC框架中研究基于模型的离线RL为我们提供了一种方便的方法,通过将策略优化与策略评估分开来分别研究批评者的统计复杂性和参与者的计算复杂性。具体地说,在评论家中,我们通过最小化过渡模型P的约束集上的Q函数,在每次迭代t中找到悲观的Q函数。评论家返回模型Pt,使得Pt(·|s,a)接近P∗ 当状态-动作对(s,a)位于离线分发的支持中时∗ 是地面真实过渡模型。因此,当(s,a)位于离线数据所涵盖的某些政策π†引起的占用率度量的支持时,估计误差不会增加很多。这样的设计能够返回由离线数据覆盖的比较器策略引起的值函数的准确估计,但当比较器政策不被离线数据覆盖时,返回悲观值函数。在参与者部分,我们通过有限维空间中的线性特征跨度来近似Q函数,并使用自然政策梯度(Agarwal等人,2021)来更新政策参数。我们研究了由于每次迭代中的占用度量(由转移模型Pt和策略πt引起)的变化而导致的策略梯度步长引起的分布偏移。通过引入一个有限的集中系数,我们证明了来自反应器中Q的线性近似的传递误差也是可以控制的。综上所述,我们设计了一种在一般函数近似下的计算可处理算法,用于具有理论保证的基于模型的离线RL。我们的主要贡献有三方面。首先,与Uehara和Sun(2021)关于基于模型的离线RL的最新理论工作相比,提出的PeMACO算法不仅具有PAC保证,而且可以在实践中实现。其次,与无模型RL文献相比,我们不需要Bellman完备性假设。第三,本工作中的理论分析提供了一个基本框架,并为基于AC的离线模型算法的未来发展打开了大门。从统计角度处理过渡模型和近似Q函数的其他方法可以适用于我们的理论框架。