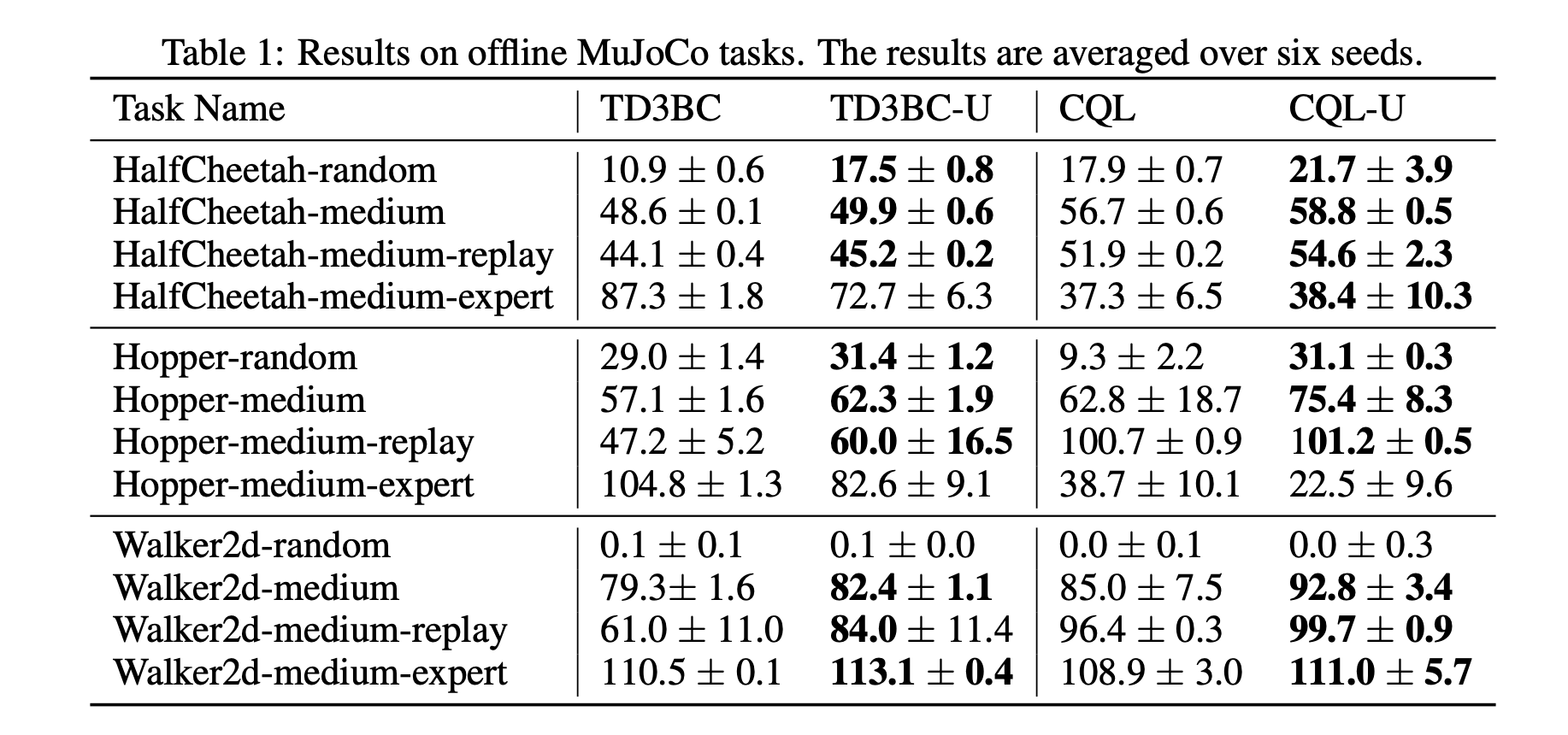
离线强化学习在Q值函数中存在外推误差。此外,大多数方法在培训期间对策略实施一致的约束,而不管策略的分发级别如何。我们提出了悲观策略迭代,它保证在训练策略的分布下Q值误差很小,并限制了训练策略的值函数的次优差距。同时,悲观政策迭代的核心组成部分是一个水平灵活的不确定性量词,它可以根据区域不确定性设置约束。实证研究表明,所提出的方法可以提高基线方法的性能,并且对约束的规模具有鲁棒性。此外,需要灵活的不确定性范围来确定分布外区域。

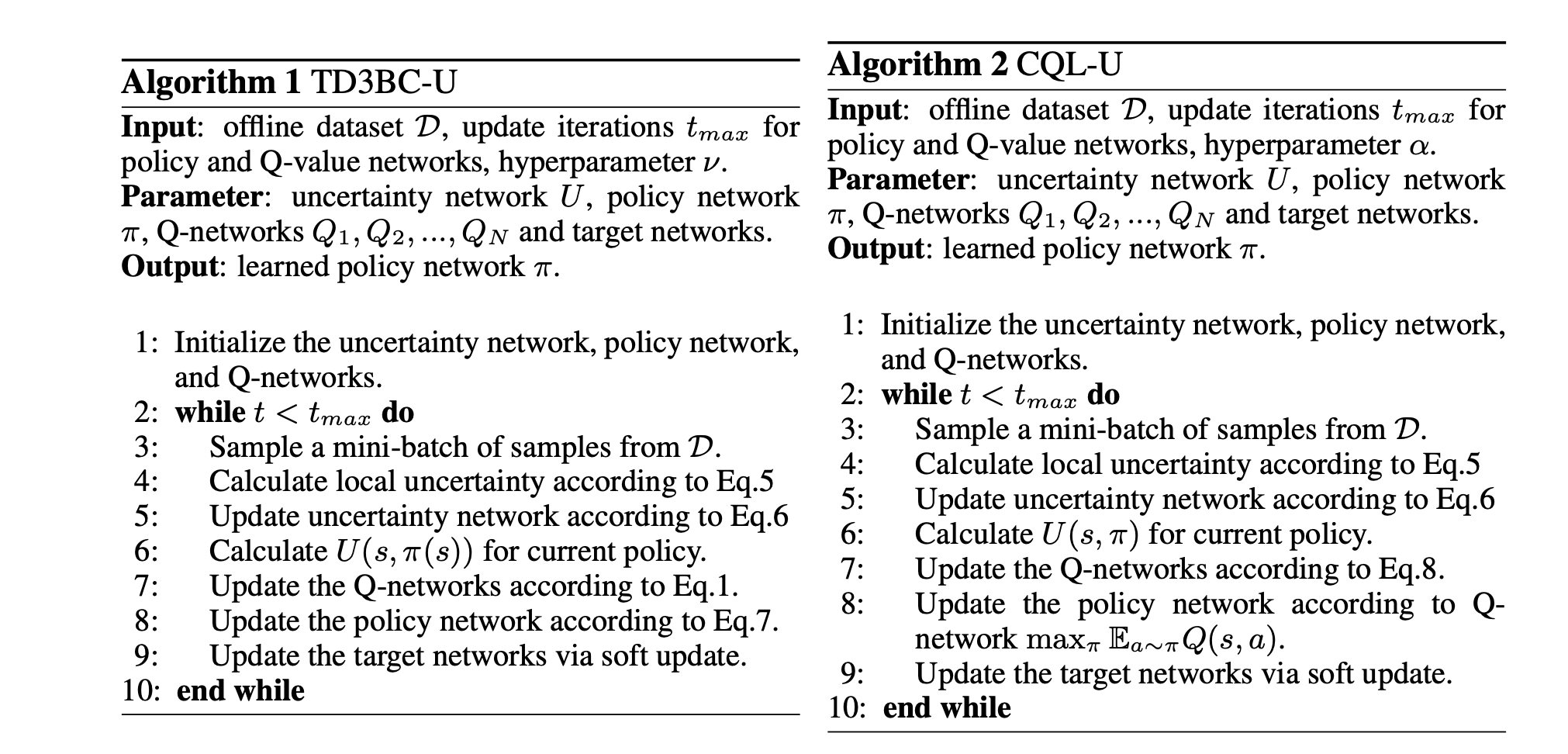
离线强化学习(RL)由于其安全性和大数据集的可用性,有望应用于医疗(Gottesman等人,2018;Wang等人,2018)、广告系统(Chen等人,2019)和自动驾驶(Sallab等人,2017;Kendall等人,201)。然而,离线RL严重存在分发外(OOD)问题(Fujimoto等人,2019)。从限制的角度来看,最近缓解OOD问题的尝试可以分为两个分支:政策限制方法(Wu等人,2019;Kumar等人,201)和Q-限制方法(Kumar et al.,2020;Cheng等人,2022)。前者将训练后的策略规则化为接近行为策略,而后者惩罚OOD动作的Q值。尽管目前的方法已经取得了令人满意的性能,但一些问题尚未得到解决。最重要的挑战是,分布内约束仍然无法消除迭代非策略评估引入的Q值估计误差(Brandfonbrener等人,2021)。可以通过强制执行强约束来控制错误,但这可能会限制发现隐藏在数据集中的最佳策略的潜力。IQL(Kostrikov等人,2022)和一步RL(Brandfonbrener等人,2021)可以通过利用样本内学习避免外推错误,而无需查询数据集中看不见的动作的值。然而,样本学习也可能限制策略的泛化能力。我们预计,Bellman方程中的目标动作仍然由经过训练的策略产生,从而享有泛化收益。在这种情况下,我们希望在经过训练的策略分布下,Q值误差较小。另一个问题是,无论策略的OOD级别如何,大多数方法都会对策略实施一致的约束。为了解决这个问题,引入了不确定性估计。在政策约束方法中,UWAC(Wu等人,2021)利用MC辍学(Gal&Ghahramani,2016)来估计给定状态动作对的不确定性。然而,不确定性估计器只关注局部过渡的不确定性,而忽略了未来轨迹的不确定性(称为全局不确定性)。以图1为例,黑色和蓝色区域分别表示OOD和分布区域。代理人的目标是从左向右移动。在图1(a)中,两个橙色点的局部不确定性是相同的,但代理在左点比在右点更保守。因此,全局不确定性估计器是必要的。然而,对于政策限制方法的全球不确定性仍缺乏研究。对于Q-限制方法,SACN(An等人,2021)、MOPO(Yu等人,2020)和PBRL(Bai等人,2022)将局部不确定性显式或隐式地视为内在回报,并将其嵌入Q值。全局不确定性是已知的,但它必须与Q值评估共享相同的范围,通常接近1。这个广阔的视野可能会使政策在未来考虑得太远,而忽略了附近的危险。当使用Q值的贴现因子时,图1(b)和图1(c)中的橙色点具有相同的全局不确定性。然而,图1(b)中橙色点处的试剂应比图1(c)中的试剂更保守。因此,需要一个具有灵活视界的全局不确定性估计器。在本文中,我们分析了离线RL中策略迭代的错误传播,并提出了基于全局不确定性量词的悲观策略迭代,以限制训练策略的值函数的次优差距。全局不确定性以贝尔曼式独立估计,以允许不确定性传播。我们在策略限制基线上实例化悲观策略迭代,以根据不确定性更新策略。此外,Q-限制方法,如CQL(Kumar et al.,2020)可以用全局不确定性来增强,以实现可延展的惩罚。此外,全局不确定性估计器可以具有与Q值评估不同的范围,这可以在时域中具有灵活的注意力,以允许区域不确定性。我们表明,更小的视界也会带来更严格的泛化界限。关于“穿越森林”的实验表明,全球不确定性有助于识别OOD区域,选择适度的地平线很重要。实验结果表明,我们提出的方法在大多数D4RL任务上优于基线(Fu等人,2020),并且对约束的规模是鲁棒的。