Meta-RL is meta-learning on reinforcement learning tasks. After trained over a distribution of tasks, the agent is able to solve a new task by developing a new RL algorithm with its internal activity dynamics. This post starts with the origin of meta-RL and then dives into three key components of meta-RL.
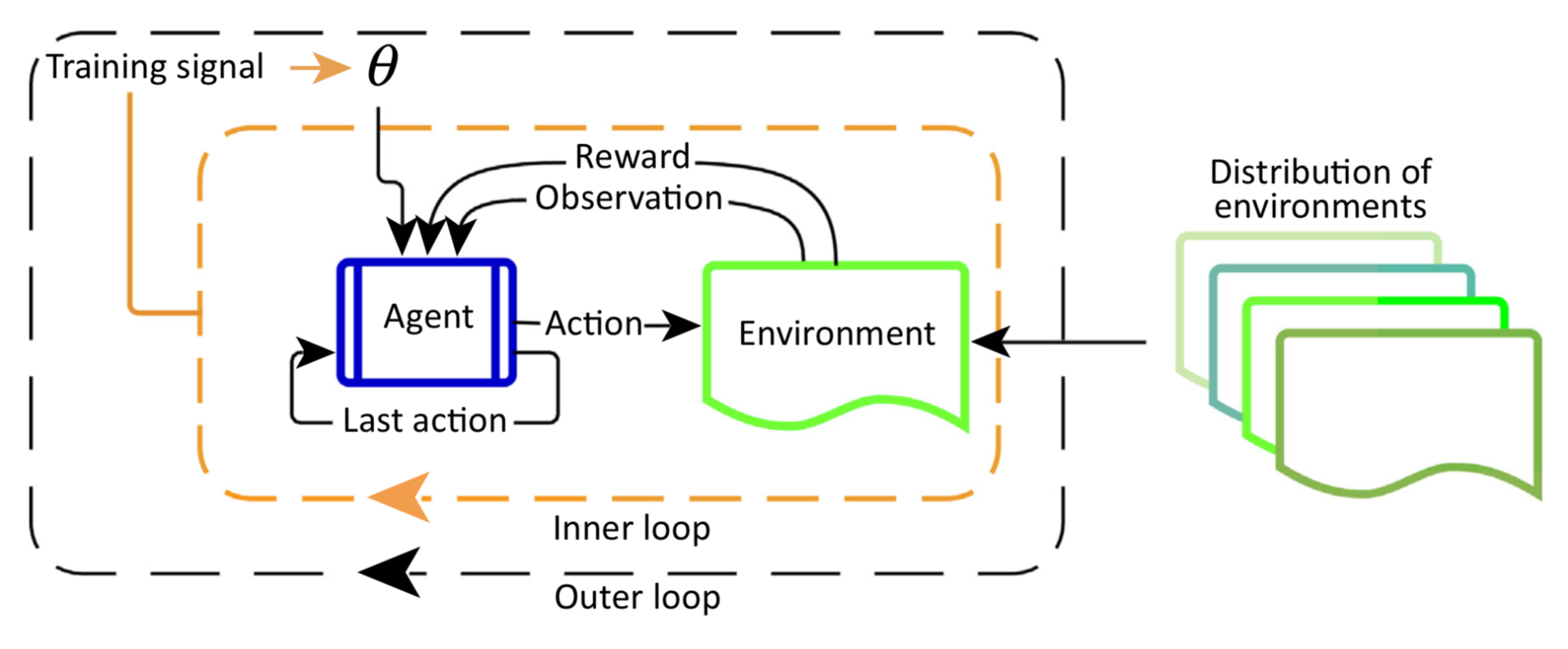
Key Components
There are three key components in Meta-RL:
⭐ A Model with Memory
A recurrent neural network maintains a hidden state. Thus, it could acquire and memorize the knowledge about the current task by updating the hidden state during rollouts. Without memory, meta-RL would not work.
⭐ Meta-learning Algorithm
A meta-learning algorithm refers to how we can update the model weights to optimize for the purpose of solving an unseen task fast at test time. In both Meta-RL and RL2 papers, the meta-learning algorithm is the ordinary gradient descent update of LSTM with hidden state reset between a switch of MDPs.
⭐ A Distribution of MDPs
While the agent is exposed to a variety of environments and tasks during training, it has to learn how to adapt to different MDPs.