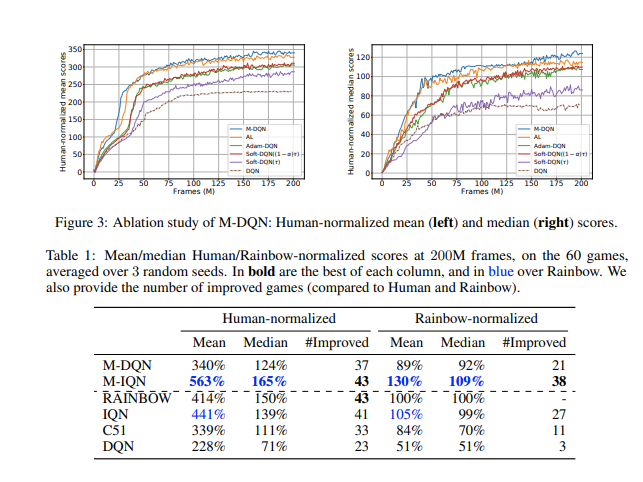
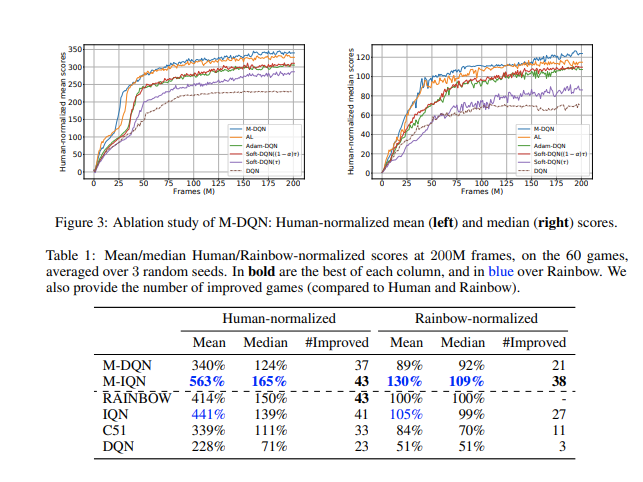
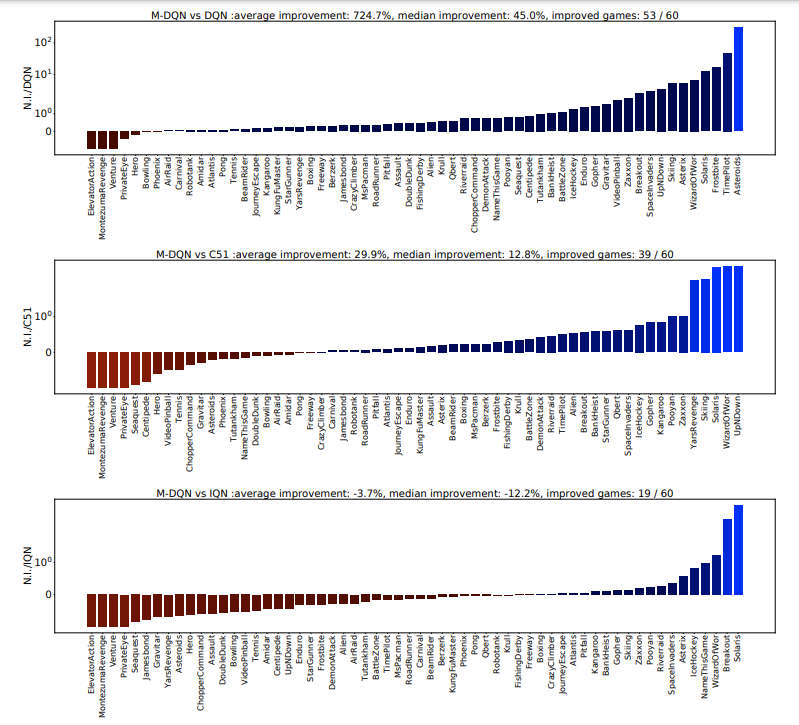
Bootstrapping 是强化学习 (RL) 的核心机制。大多数算法基TD,用它们当前对该值的估计替换过渡状态的真实值。然而,可以利用另一个估计来引导 RL: the current policy. 。我们的核心贡献在于一个非常简单的想法:将缩放对数策略添加到即时奖励中。我们表明,以这种方式稍微修改深度 Q 网络 (DQN) 提供了一个与 Atari 游戏中的分布式方法相比具有竞争力的智能体,而无需使用分布式 RL、n 步返回或优先重放。为了证明这个想法的多功能性,我们还将它与隐式分位数网络 (IQN) 一起使用。由此产生的智能体在 Atari 上的表现优于 Rainbow,安装了一个新的 State of the Art,对原始算法进行了很少的修改。为了增加这项实证研究,我们对发生的事情提供了强有力的理论见解——隐式 Kullback-Leibler 正则化和行动差距的增加。