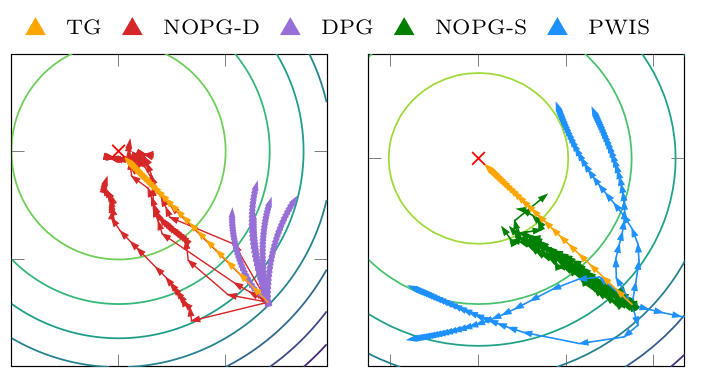
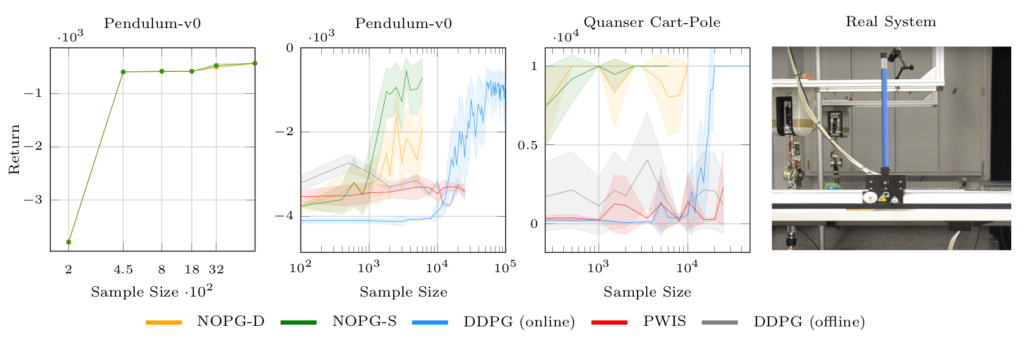
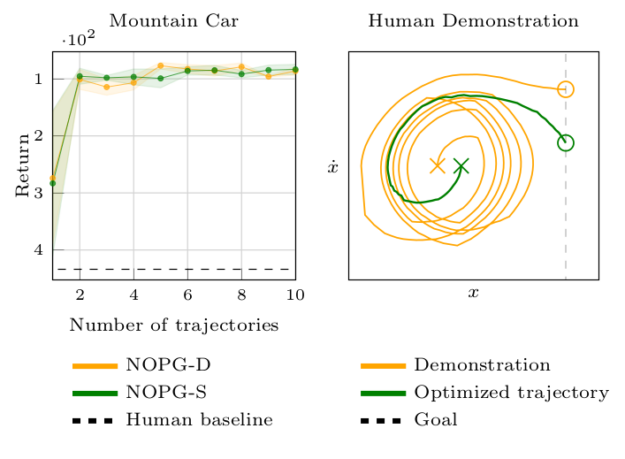
强化学习 (RL) 算法受到高样本复杂性的影响,在许多广泛流行的策略梯度算法中,尤其需要与环境进行密集交互,这些算法使用在策略样本执行更新,低效率的代价在现实世界的场景中变得显而易见,例如交互驱动的机器人学习,其中 RL 的成功相当有限。作者通过建立off-policy算法的一般样本效率来解决这个问题。使用非参数回归和密度估计方法,以一种有原则的方式构造了一个非参数 Bellman 方程,这使得能够获得价值函数的封闭形式估计,并分析表达完整的策略梯度。作者对估计进行了理论分析,,并且经验表明方法比最先进的策略梯度方法具有更好的样本效率。