Sparse Reward 是指稀疏回报,在很多强化学习场景中,大多数情况下是没有回报的,举个例子来说:
假设你要训练一个机器手臂,然后桌上有一个螺丝钉跟螺丝起子,那你要训练它用螺丝起子把螺丝钉栓进去,这是很难的。因为一开始你的 agent 是什么都不知道的,它唯一能够做不同的 action 的原因是 exploration,也就是会有一些随机性,让它去采取一些过去没有采取过的 action,那你要随机到说,它把螺丝起子捡起来,再把螺丝栓进去,然后就会得到 reward 1,这件事情是永远不可能发生的。
如果环境中的 reward 非常 sparse,reinforcement learning 的问题就会变得非常的困难,但是人类可以在非常 sparse 的 reward 上面去学习。我们的人生通常多数的时候,我们就只是活在那里,都没有得到什么 reward 或是 penalty。但是,人还是可以采取各种各式各样的行为。所以,一个真正厉害的 AI 应该能够在 sparse reward 的情况下也学到要怎么跟这个环境互动。
阅读本文后可以继续阅读的论文:
facebook参加VizDoom比赛的论文:https://download.csdn.net/download/qq_33302004/16757546
分层强化学习的论文:
https://download.csdn.net/download/qq_33302004/16757571
常见的处理方法有三种:
文章目录
1\. Reward Shaping
2\. Curriculum Learning
3\. Hierarchical RL
1. Reward Shaping
reward shaping是指:在我们的agent与environment进行交互时,我们人为的设计一些reward,从而“指挥”agent,告诉其采取哪一个action是最优的,而这个reward并不是environment对应的reward,这样可以提高我们estimate Q-function时的准确性。
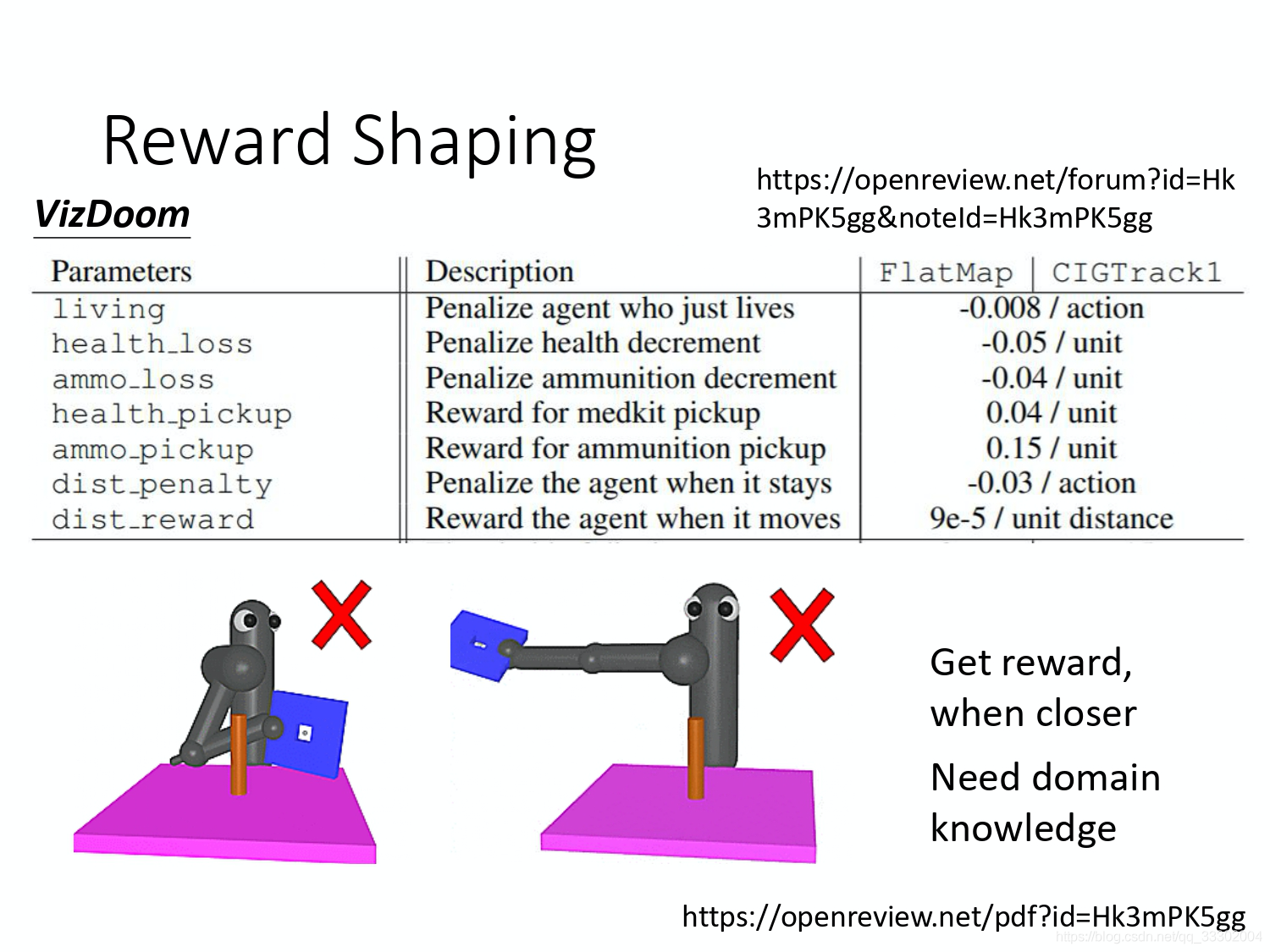
在这里插入图片描述
举例来说,这个例子是 Facebook 玩 VizDoom 的 agent。VizDoom 是一个第一人射击游戏,在这个射击游戏中,杀了敌人就得到 positive reward,被杀就得到 negative reward。他们设计了一些新的 reward,用新的 reward 来引导 agent 让他们做得更好,这不是游戏中真正的 reward。比如说掉血就扣 0.05 的分数,弹药减少就扣分,捡到补给包就加分,呆在原地就扣分,移动就加分。 活着会扣一个很小的分数,因为不这样做的话,machine 会只想活着,一直躲避敌人,这样会让 machine 好战一点。表格中的参数都是调出来的。
Reward shaping 是有问题的,因为我们需要 domain knowledge,举例来说,机器人想要学会的事情是把蓝色的板子从这个柱子穿过去。机器人很难学会,我们可以做 reward shaping。一个貌似合理的说法是,蓝色的板子离柱子越近,reward 越大。但是 machine 靠近的方式会有问题,它会用蓝色的板子打柱子。而我们要把蓝色板子放在柱子上面去,才能把蓝色板子穿过柱子。 这种 reward shaping 的方式是没有帮助的,那至于什么 reward shaping 有帮助,什么 reward shaping 没帮助,会变成一个 domain knowledge,你要去调的。
2. Curriculum Learning
curriculum learning是指:一种广义的用在RL的训练agent的方法,其在input训练数据的时候,采取由易到难的顺序进行input,也就是认为设计它的学习过程,这个方法在ML和DL中都会普遍使用。
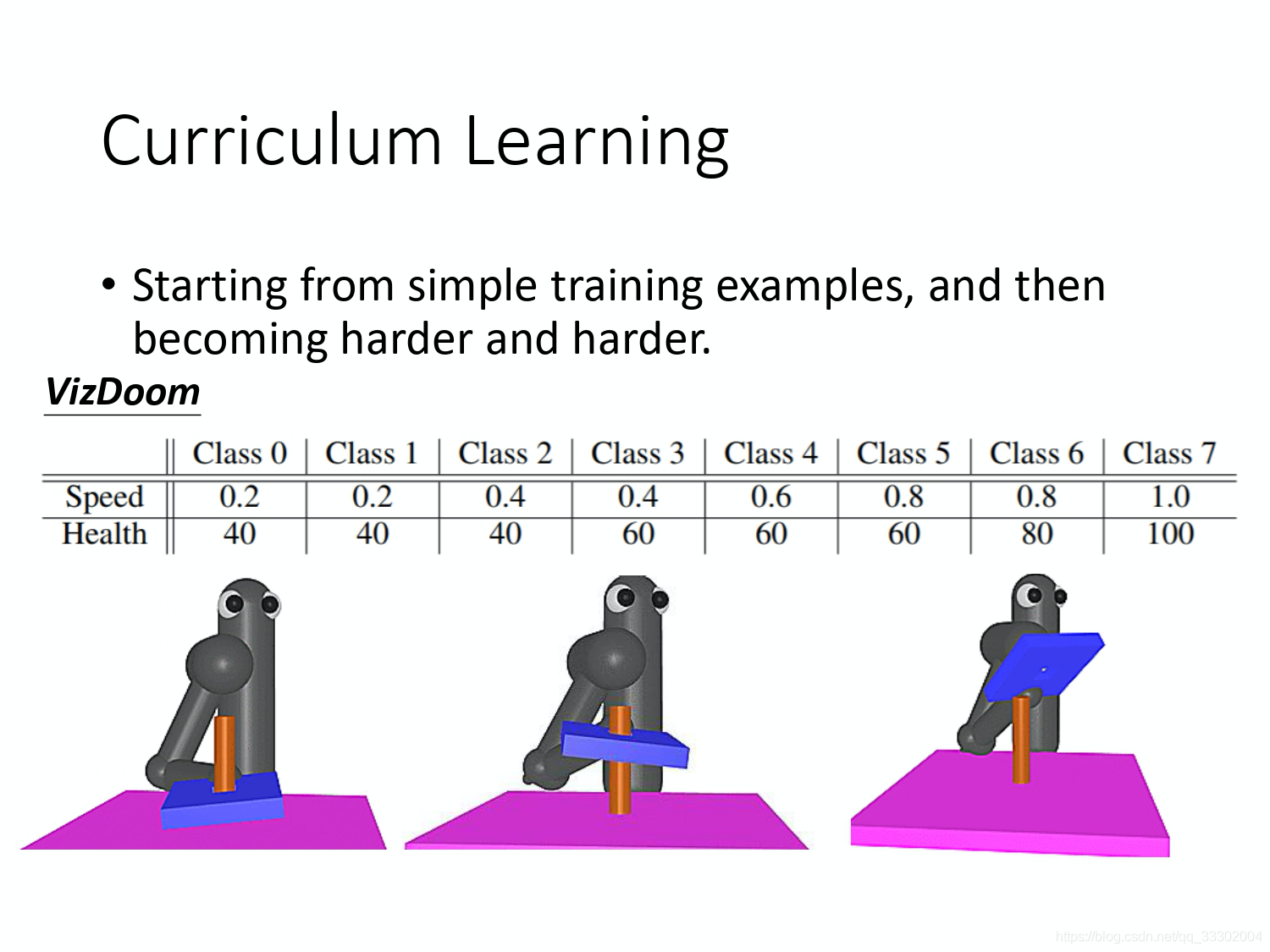
举例来说,在 Facebook 玩 VizDoom 的 agent 里面,他们是有为机器规划课程的。先从课程 0 一直上到课程 7。在这个课程里面,怪物的速度跟血量是不一样的。所以,在越进阶的课程里面,怪物的速度越快,然后他的血量越多。在 paper 里面也有讲说,如果直接上课程 7,machine 是学不起来的。你就是要从课程 0 一路玩上去,这样 machine 才学得起来。
再举个例子,把蓝色的板子穿过柱子,怎么让机器一直从简单学到难呢?
如第一张图所示,也许一开始机器初始的时候,它的板子就已经在柱子上了。这个时候,机器要做的事情只有把蓝色的板子压下去,就结束了。这比较简单,它应该很快就学的会。
如第二张图所示,这边就是把板子挪高一点,所以它有时候会很笨的往上拉,然后把板子拿出来了。如果它压板子学得会的话,拿板子也比较有机会学得会。假设它现在学的到说,只要板子接近柱子,它就可以把这个板子压下去的话。接下来,你再让它学更 general 的 case。
如第三张图所示,一开始,让板子离柱子远一点。然后,板子放到柱子上面的时候,它就会知道把板子压下去,这个就是 curriculum learning 的概念。当然 curriculum learning 有点 ad hoc(特别),就是需要人去为机器设计它的课程。
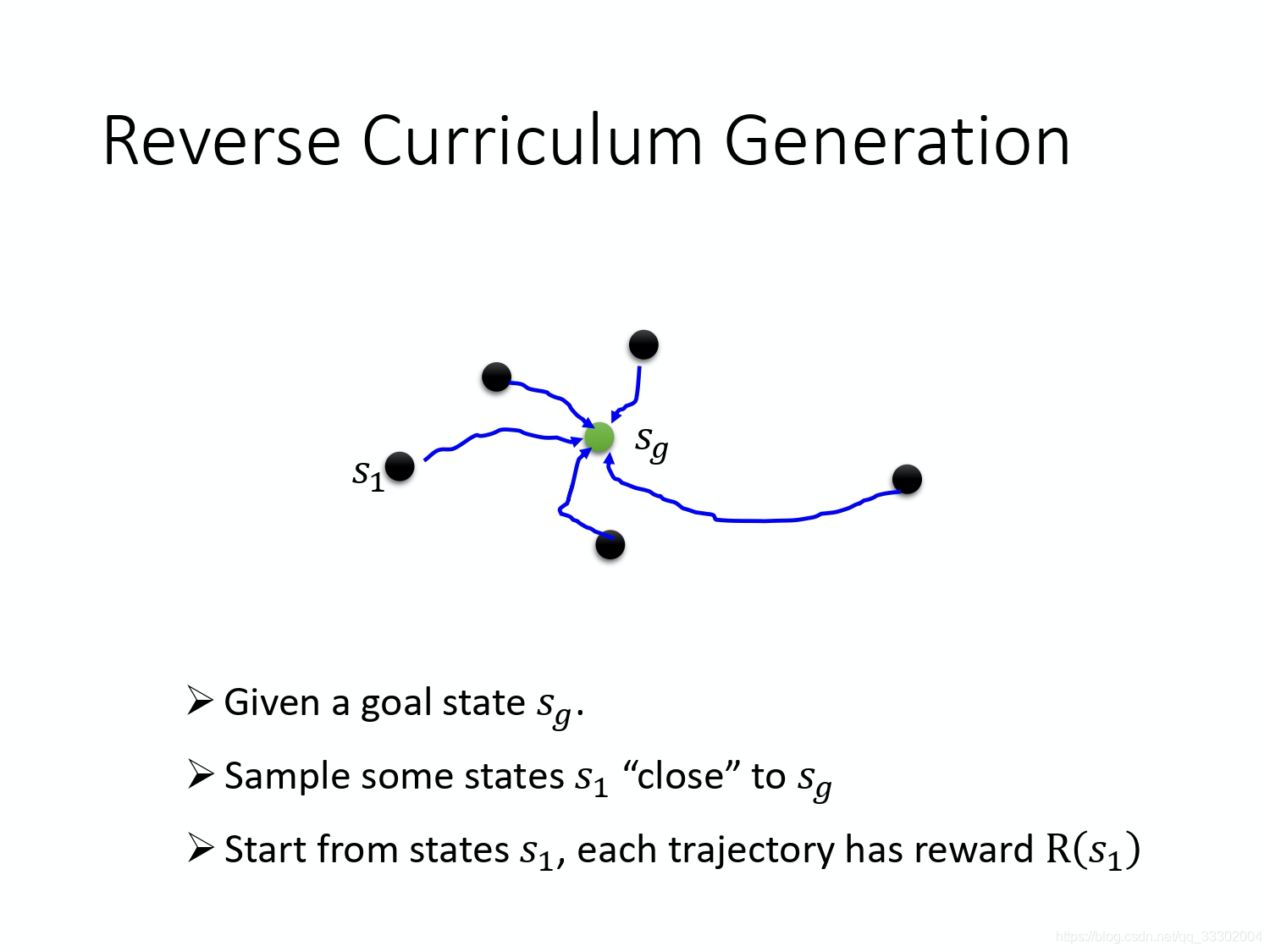
上面提到的课程是需要认为去设计的,这里有一种更加general的方法:Reverse Curriculum Generation。
goal state 是指我们的目标状态,比如上面例子中,把板子放到柱子里面。接下来我们根据goal state去找和它比较接近的state,至于如何定义接近需要我们去定义。接下来就从这个比较接近的state s 1 s_1 s1出发,看看能不能达到goal state s g s_g sg。
在这里插入图片描述
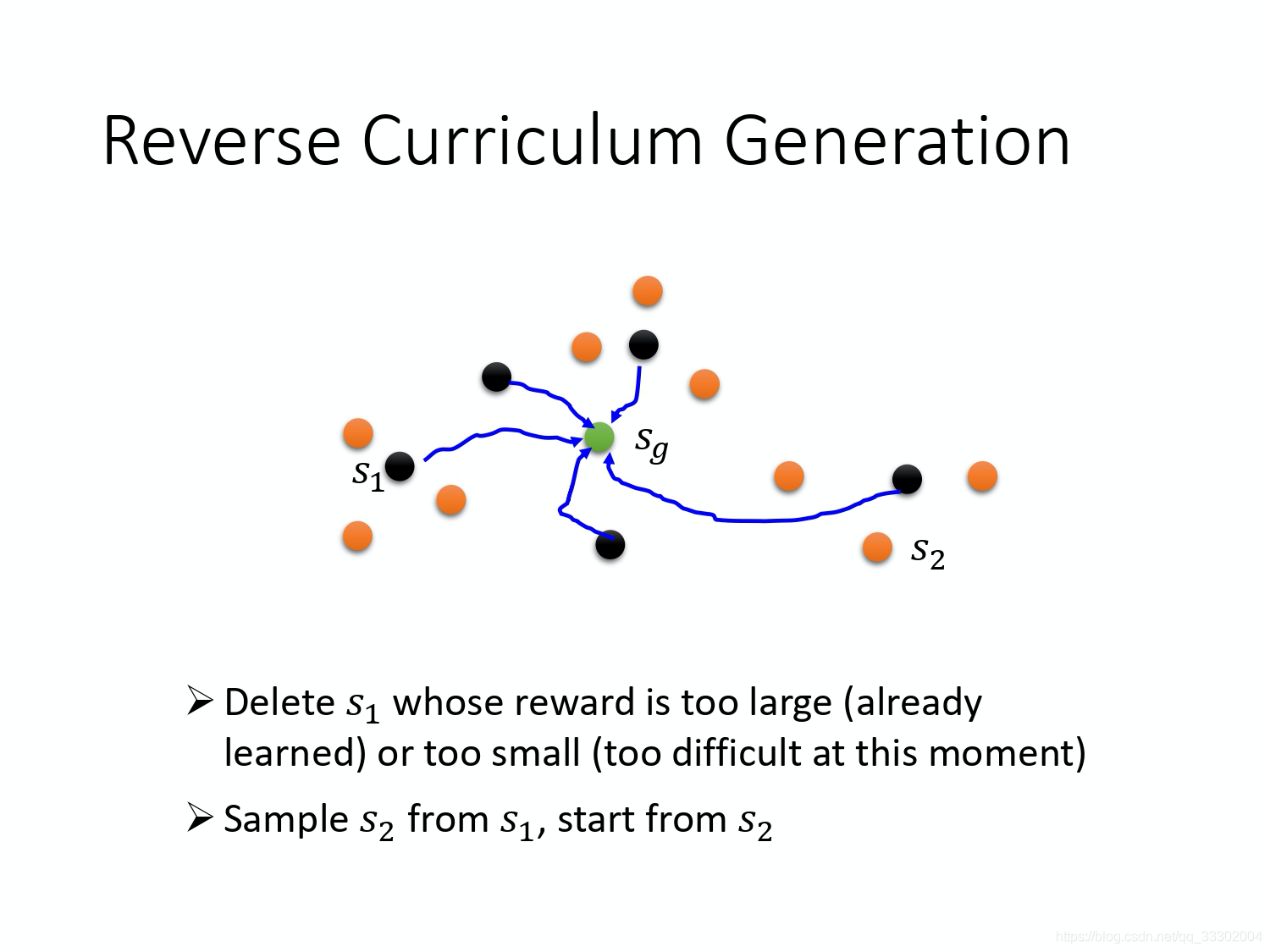
当然,在挑选 $S_{1}$时我们会去掉特别复杂或者特别简单的case,保留难度适中的状态,这个难度适中也需要我们自己去定义。如果从 s 1 s_1 s1可以完成任务,我们就可以逐步调远距离(也就是增加学习难度)。刚才讲的是 curriculum learning,就是你要为机器规划它学习的顺序。而 reverse curriculum learning 是从 gold state 去反推,就是说你原来的目标是长这个样子,我们从目标去反推,所以这个叫做 reverse。
3. Hierarchical RL
hierarchical (分层) reinforcement learning是指:将一个大型的task,横向或者纵向的拆解成多个 agent去执行。其中,有一些agent 负责比较high level 的东西,负责订目标,然后它订完目标以后,再分配给其他的 agent把它执行完成。(看教程的 hierarchical reinforcement learning部分的示例就会比较明了)
这样的想法其实也是很合理的。因为人在一生之中,并不是时时刻刻都在做决定。举例来说,假设你想要写一篇 paper,你会说就我先想个梗这样子,然后想完梗以后,你还要跑个实验。跑完实验以后,你还要写。写完以后呢,你还要这个去发表。每一个动作下面又还会再细分,比如说怎么跑实验呢?你要先 collect data,collect 完 data 以后,你要再 label,你要弄一个 network,然后又 train 不起来,要 train 很多次。然后重新 design network 架构好几次,最后才把 network train 起来。
所以,我们要完成一个很大的 task 的时候,我们并不是从非常底层的那些 action 开始想起,我们其实是有个 plan。我们先想说,如果要完成这个最大的任务,那接下来要拆解成哪些小任务。每一个小任务要再怎么拆解成小小的任务。举例来说,叫你直接写一本书可能很困难,但叫你先把一本书拆成好几个章节,每个章节拆成好几段,每一段又拆成好几个句子,每一个句子又拆成好几个词汇,这样你可能就比较写得出来,这个就是分层的 reinforcement learning 的概念。
在这里插入图片描述
上图是论文中的例子。实际上呢,这里面就做了一些比较简单的游戏,这个是走迷宫,蓝色是 agent,蓝色的 agent 要走到黄色的目标。这边也是,这个单摆要碰到黄色的球。那愿景是什么呢?
在这个 task 里面,它只有两个 agent ,下层的一个 agent 负责决定说要怎么走,上层的 agent 就负责提出愿景。虽然,实际上你可以用很多层,但 paper 就用了两层。
走迷宫的例子是说粉红色的这个点代表的就是愿景。上层这个 agent,它告诉蓝色的这个 agent 说,你现在的第一个目标是先走到这个地方,蓝色的 agent 走到以后,再说你的新的目标是走到这里。蓝色的 agent 再走到以后,新的目标在这里。接下来又跑到这边,最后希望蓝色的 agent 就可以走到黄色的这个位置。
单摆的例子也一样,就是粉红色的这个点代表的是上层的 agent 所提出来的愿景,所以这个 agent 先摆到这边,接下来,新的愿景又跑到这边,所以它又摆到这里。然后,新的愿景又跑到上面。然后又摆到上面,最后就走到黄色的位置了。这个就是 hierarchical 的 reinforcement learning。
最后总结下分层强化学习。分层强化学习是指将一个复杂的强化学习问题分解成多个小的、简单的子问题,每个子问题都可以单独用马尔可夫决策过程来建模。这样,我们可以将智能体的策略分为高层次策略和低层次策略,高层次策略根据当前状态决定如何执行低层次策略。这样,智能体就可以解决一些非常复杂的任务。
————————————————
版权声明:本文为CSDN博主「志远1997」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_33302004/article/details/115868096