推荐缘由:本文是Pieter Abbeel教授率先提出的关于加速强化学习方法的论文,值得了解。

最近几年,深度强化学习在各行各业已经有了很成功的应用,但实验的周转时间(turn-around time)仍然是研究和实践中的一个关键瓶颈。 该论文研究如何在现有计算机上优化现有深度RL算法,特别是CPU和GPU的组合。 且作者确认可以调整策略梯度和Q值学习算法以学习使用许多并行模拟器实例。 通过他们进一步发现可以使用比标准尺寸大得多的批量进行训练,而不会对样品复杂性或最终性能产生负面影响。 同时他们利用这些事实来构建一个统一的并行化框架,从而大大加快了两类算法的实验。 所有神经网络计算都使用GPU,加速数据收集和训练。在使用同步和异步算法的基础上,结果标明在使用整个DGX-1在几分钟内学习Atari游戏中的成功策略。
注:周转时间(turnaround time):训练模型的时间
一、背景和相关内容
目前的深度强化学习严重依赖于经验评估,因此turnaround 时间成为一个关键的限制因素,尽管存在这一重要瓶颈,但许多参考实施方案不能满足现代计算机的吞吐量潜力,在这项工作中,作者研究如何在不改变其基本公式的情况下调整深度RL算法,并在一台机器中更好地利用多个CPU和GPU进行实验。 结果标明,显着提高了硬件利用率的效率和规模,从而提高了学习速度。
今天比较领先的深度RL算法大致分为两类:
(i)策略梯度方法 ,以Asynchronous Advantage Actor-Critic(A3C)(Mnih et al 2016)是一个代表性的例子,
(ii)Q值学习方法 ,一个代表性的例子是Deep Q-Networks(DQN)(Mnih等,2015)。
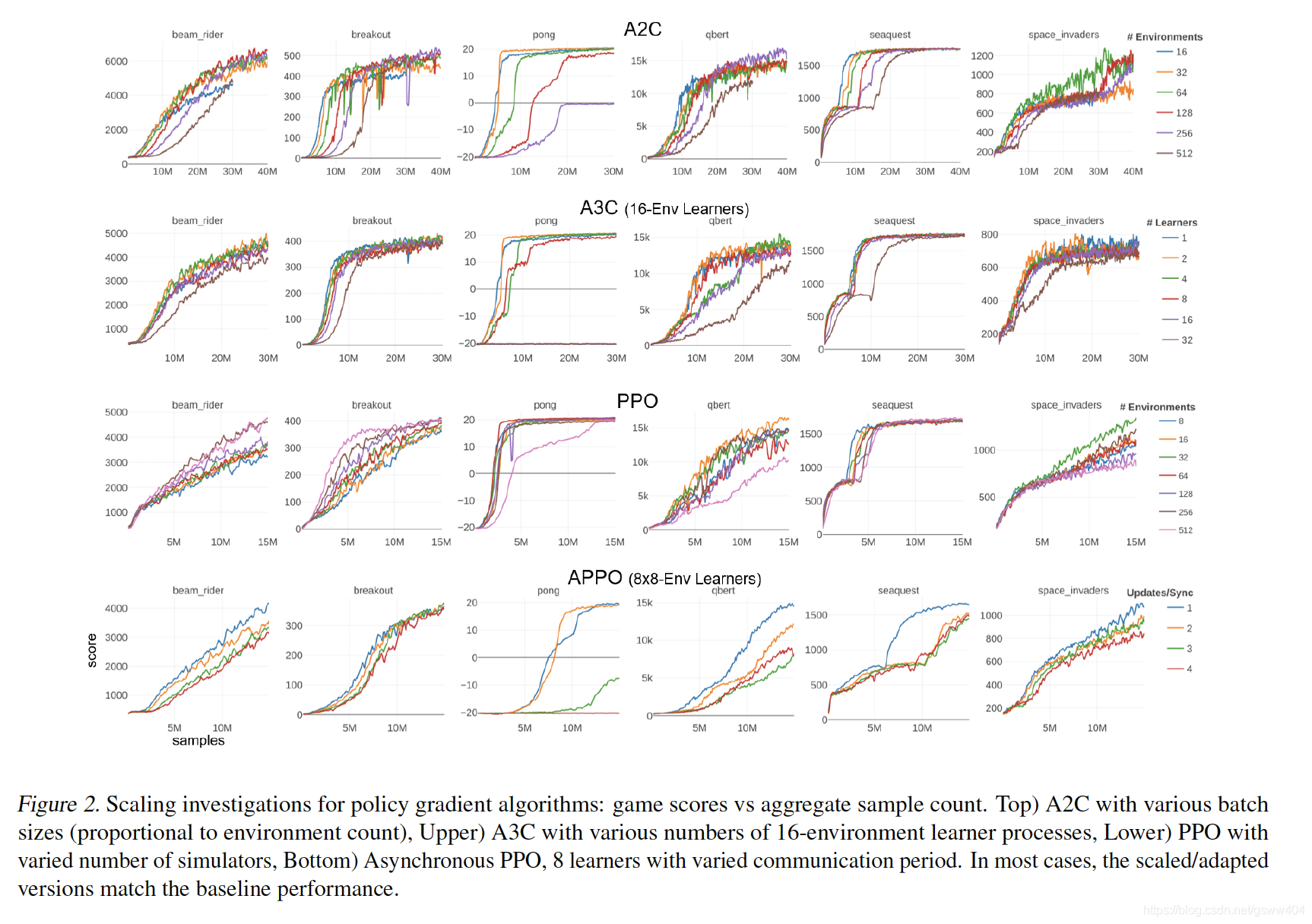
传统上,这两个系列出现在不同的实现中并使用不同的硬件资源,该篇paper作者将它们统一在相同的扩展框架下。作者贡献了并行化深度RL的框架,包括用于推理和训练的GPU加速的新技术。演示了以下算法的多GPU版本:Advantage Actor-Critic(A3C),Proximal Policy Optimization(PPO),DQN,Categorical DQN和Rainbow。为了提供校准结果,作者通过Arcade学习环境(ALE)测试我们在重度基准测试的Atari-2600域中的实现。同时使用批量推断的高度并行采样可以加速所有实验的(turnaround)周转时间,同时发现神经网络可以使用比标准大得多的批量大小来学习,而不会损害样本复杂性或最终游戏分数。除了探索这些新的学习方式之外,作者还利用它们来大大加快学习速度。例如,
策略梯度算法在8-GPU服务器上运行,在10分钟内学会成功的游戏策略,而不是数小时。他们同样将一些标准Q值学习的持续时间从10天减少到2小时以下。或者,独立的RL实验可以与每台计算机的高聚合吞吐量并行运行。相信这些结果有望加速深度研究,并为进一步研究和发展提出建议。
另外,作者对演员评论方法的贡献在很多方面超越了目前的很多人做法,他们主要做了:改进抽样组织,使用多个GPU大大提高规模和速度,以及包含异步优化。
二、同步采样(Synchronized Sampling)
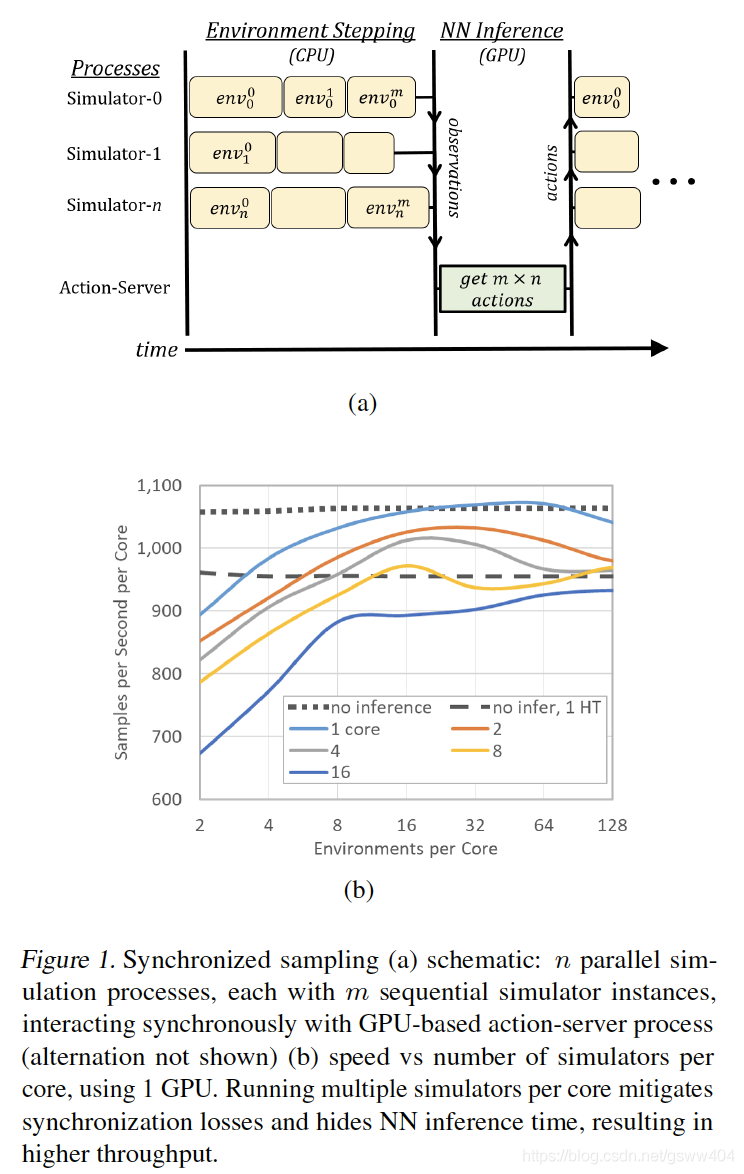
首先将多个 CPU核心 与 单个GPU 相关联。多个模拟器在CPU内核上以并行进程运行,并且这些进程以同步方式执行环境步骤。在每个步骤中,将所有单独的观察结果收集到批处理中以进行推理,在提交最后一个观察结果后在GPU上调用该批处理。 一旦动作返回,模拟器再次步骤,依此类推,系统共享内存阵列提供了动作服务器和模拟器进程之间的快速通信。
由于落后效应等同于每一步的最慢过程,同步采样可能会减速。步进时间的变化源于不同模拟器状态的不同计算负载和其他随机波动。随着并行进程数量的增加,落后者效应会恶化,但通过在每个进程中堆叠多个独立的模拟器实例来缓解它。每个进程为每个推理批处理步骤(顺序)执行所有模拟器。这种安排还允许用于推断的批量大小增加超过进程数(即CPU核心),其原理如图1(a)所示。
Sampling(采样)
一系列仅采样测量表明,尽管存在潜在的落后者,同步采样方案可以实现良好的硬件利用率。首先,我们研究了 单个GPU 在为多个环境提供推理时的容量。图1(b)显示了在播放BREAKOUT时在P100 GPU上运行训练有素的A3C-Net策略的测量结果。通过CPU核心计数归一化的聚合采样速度被绘制为在每个核心上运行的(顺序)Atari模拟器的数量的函数,交替方案的最小值是每个核心2个模拟器。不同的曲线表示运行模拟的不同数量的CPU核心。作为参考,我们包括在没有推断的情况下运行的单个核心的采样速度–单个过程的虚线,以及两个超线程中的每一个的虚线一个过程。使用推理和单核运行,采样速度随着模拟器计数而增加,直到推断时间完全隐藏。出现更高核心数的同步丢失。但是,每个核心只有8个环境,GPU甚至支持16个CPU内核,运行速度大约为无推理速度的80%。
接下来,测量了在整个8-GPU,40核服务器上并行播放BREAKOUT的同一A3C-Net的仅采样速度。 在模拟器计数为256(每个核心8个)及以上时,服务器每秒实现大于35,000个样本,或每小时5亿个仿真器帧,其结果如图:
三、学习速度(Learning Speed)
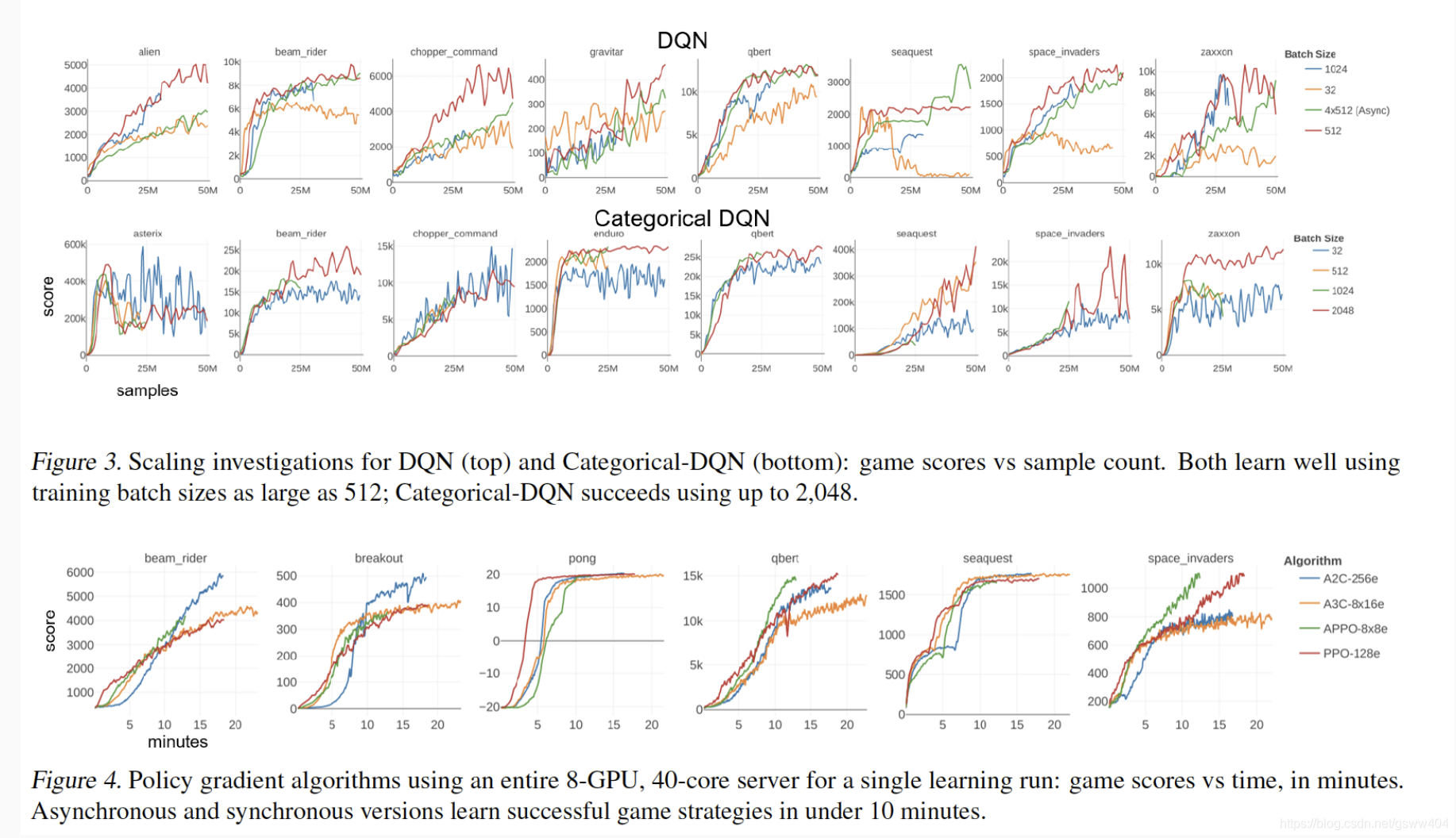
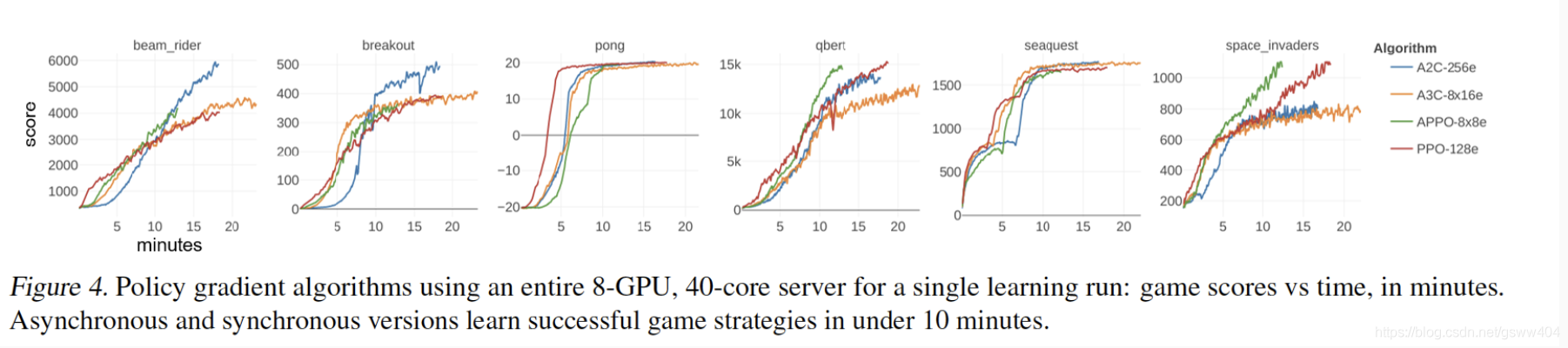
研究运行8-GPU,40核服务器(P100 DGX-1),以学习单个游戏时可获得的学习速度,作为大规模实施的示例。
四、梯度估计饱和度(Gradient Estimate Saturation)
使用A2C,我们在每次迭代时测量正常,全批次梯度和仅使用批次的一半计算的梯度之间的关系。对于小批量试剂,测量的全批次和半批次梯度之间的平均余弦相似度接近1 =P2。 这意味着两个半批渐变是正交的,高维空间中的零中心随机向量也是正交的。 然而,对于大批量学习者(例如256个环境),余弦相似性在1 = p2之上显着增加。 梯度估计的饱和度明显与较差的样本效率相关,如图顶部的学习曲线所示。