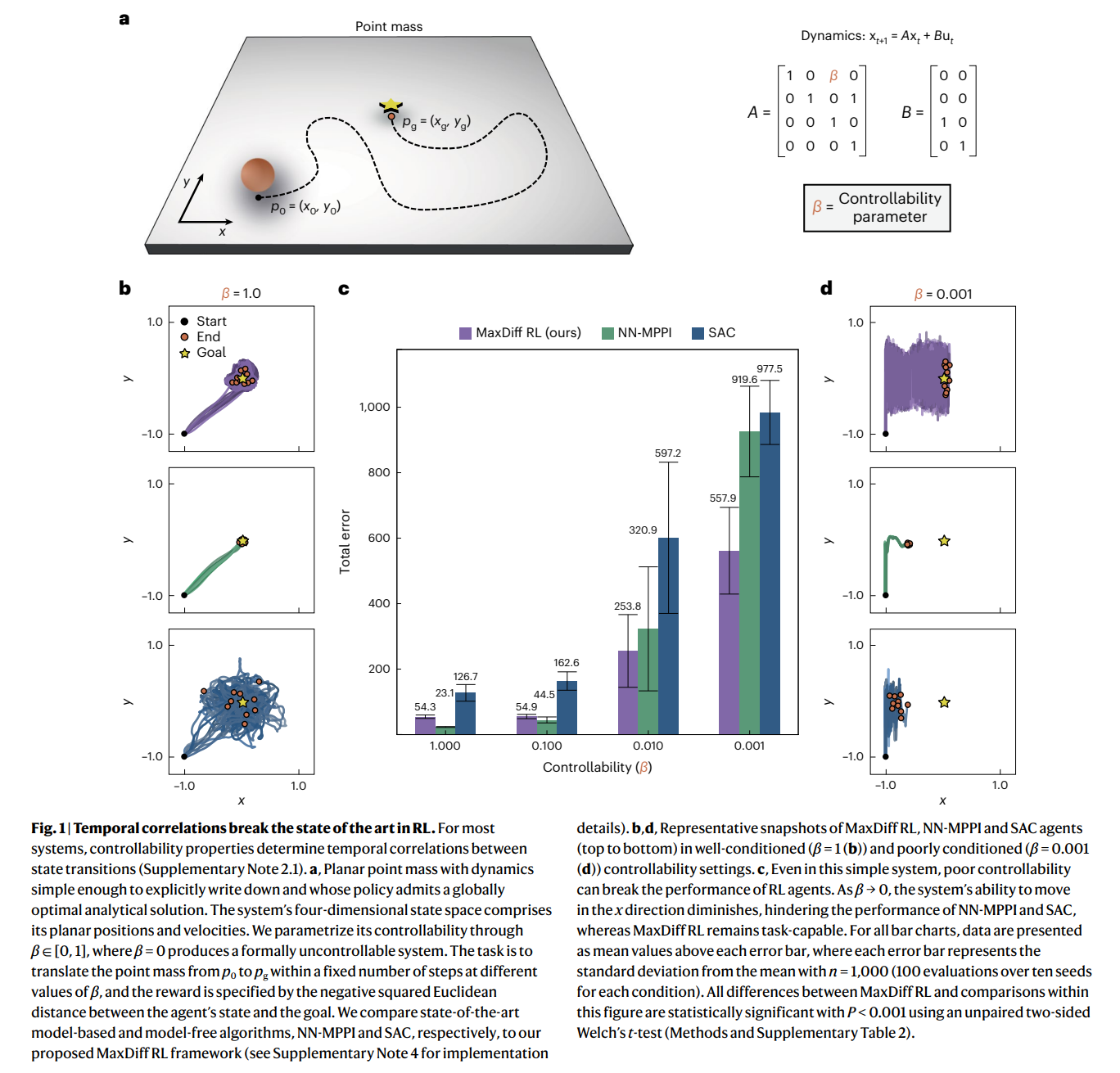
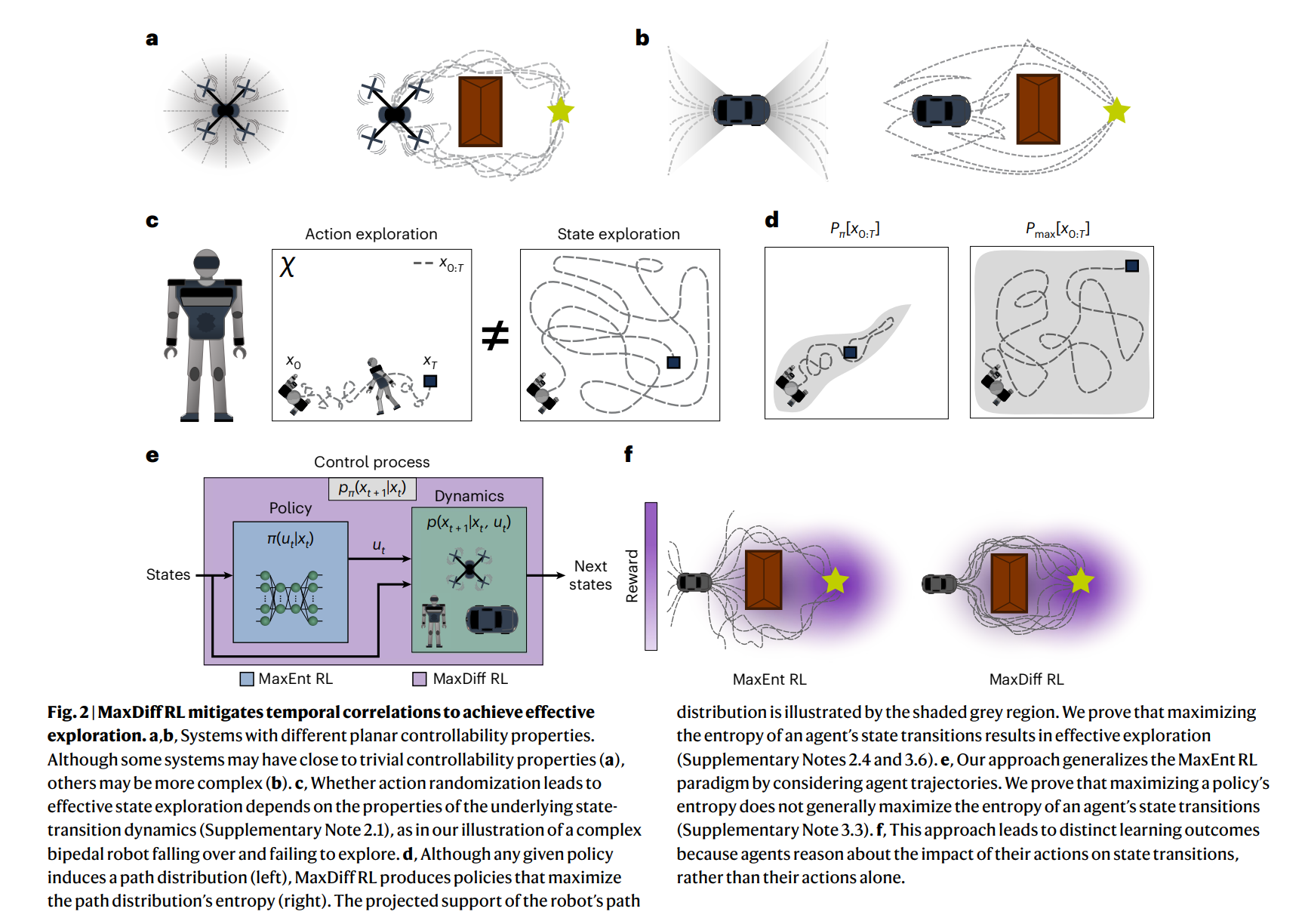
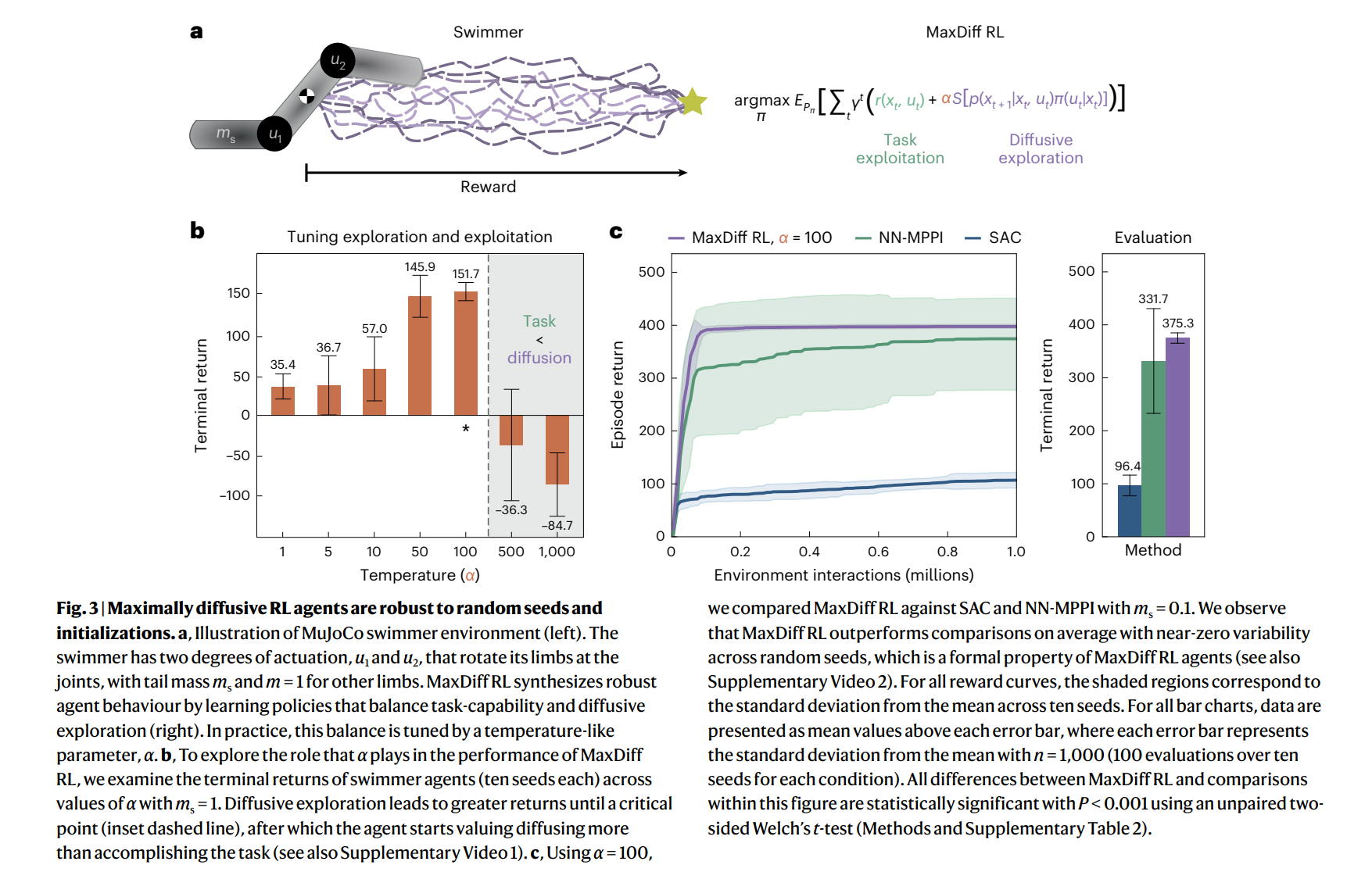
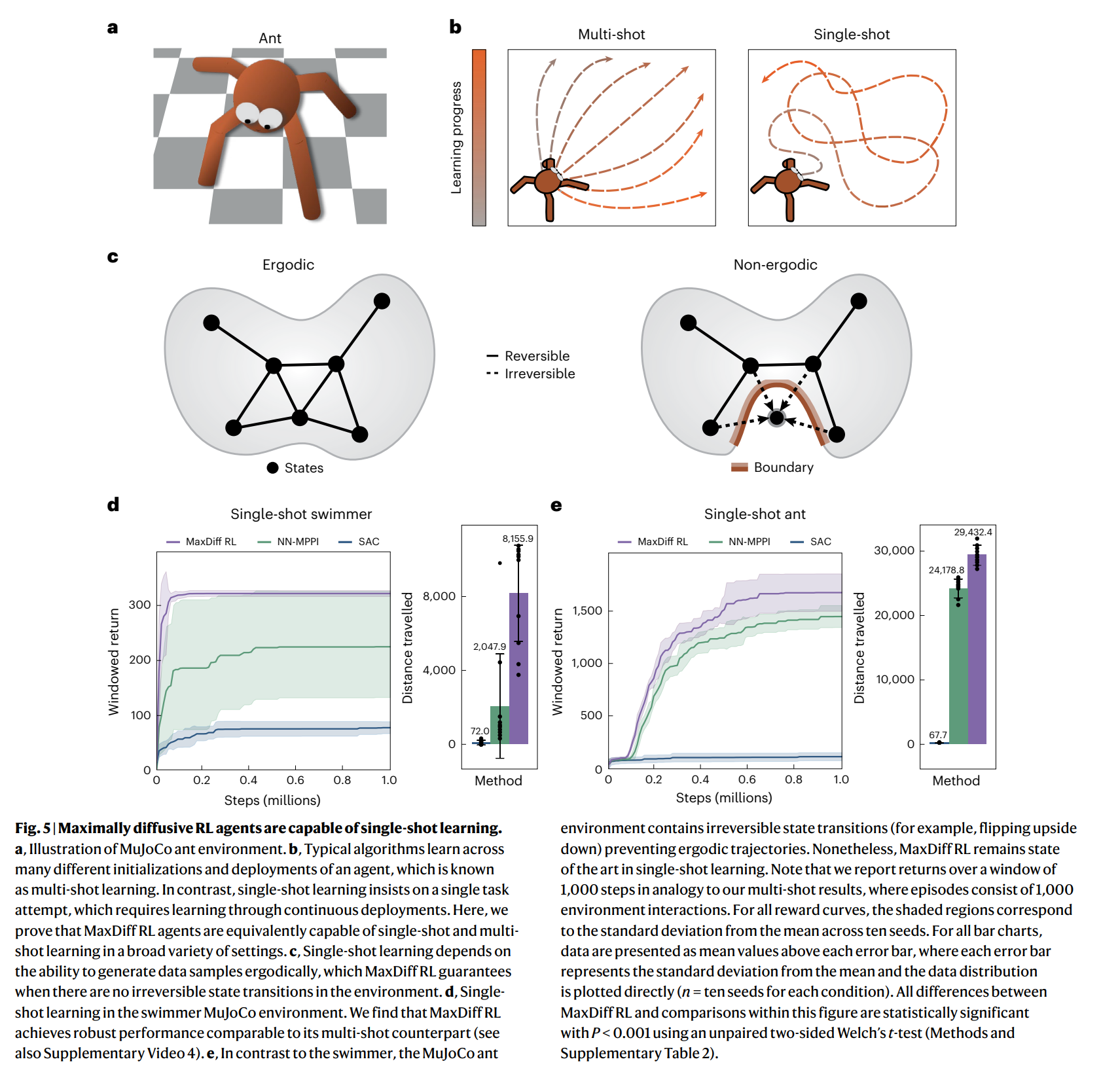
机器人和动物都通过身体和感官来体验世界。他们的化身限制了他们的体验,确保他们在空间和时间中不断展开。因此,具体化主体的体验是内在相关的。相关性给机器学习带来了根本性的挑战,因为大多数技术都依赖于数据独立且相同分布的假设。在强化学习中,数据是直接从代理人的连续经历中收集的,违反这一假设往往是不可避免的。在这里,我们通过利用遍历过程的统计力学,即我们所称的最大扩散强化学习,推导出了一种克服这一问题的方法。通过对代理体验进行去相关,我们的方法可证明能够在单个任务尝试的过程中在连续部署中进行单次学习。此外,我们证明了我们的方法推广了众所周知的最大熵技术,并在流行的基准测试中稳健地超过了最先进的性能。我们在物理、学习和控制方面的研究结果为具体强化学习主体中透明可靠的决策奠定了基础。
强化学习(RL)是一种基于人工智能体经验的灵活决策框架,其可扩展的现实世界影响的潜力已经通过深度学习架构的力量得到了证实。从控制核聚变反应堆1到击败冰壶冠军2,当RL特工能够详尽地探索他们的行为如何影响环境状态时,他们已经取得了非凡的成就。尽管取得了令人印象深刻的成就,但RL代理——尤其是深度RL代理——仍受到限制,无法在现实世界中广泛部署:它们的性能因初始化而异,样本效率低下,需要使用模拟器,而且它们很难在情景问题结构之外学习3-5。这些缺点的核心是违反了数据独立且同分布(i.i.d.)的假设,这是大多数机器学习的基础。学习通常需要i.i.d.数据,但RL代理的经验不可避免地是连续的,并在不同的时间点之间相互关联。因此,难怪许多深层RL最具影响力的进展都试图克服这一障碍6-8。近几十年来,研究人员开始认识到,破坏时间相关性对样本效率和代理性能至关重要,并试图在两个主要领域解决这一问题:优化过程和样本生成过程。当我们考虑从顺序代理-环境交互的数据库中优化策略时,已知随机批量采样可以减少时间相关性。因此,经验回放9及其多种变体10-12成功地在任务和算法之间产生了巨大的性能和样本效率提升13-15。这种简单的见解——仅仅是无序地采样体验——是deep RL取得里程碑式胜利之一的关键因素:在雅达利电子游戏基准中实现超人性能16。