在强化学习实验中,梯度L2范数理论上是收敛的,在许多论文里面这个指标也是收敛的。但是我在复现一个论文实验MD-PGT的时候将模型梯度l2范数绘制出来的时候却是不收敛,且在剧烈波动。我又从网上找了一些策略梯度的强化实验复现,但是画出来的l2范数也是不收敛的,图片如下:
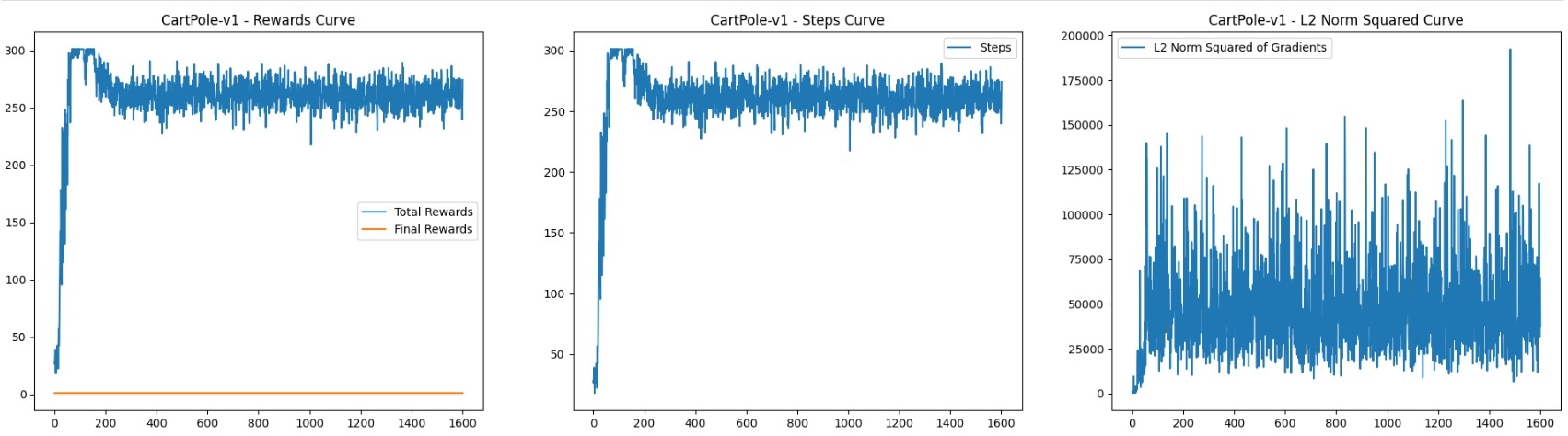
此项目是我从李宏毅深度学习教程LeeDL-Tutorial所找的一个策略梯度强化学习实验,仅修改了迭代次数与增加模型梯度L2范数计算与绘制部分代码,可以看出奖励是呈收敛趋势的,但是画出来的梯度范数图却急剧波动,与我所复现的论文实验图绘制出来的梯度图趋势差不多。运行的代码如下:
# 加载需要的包
from pyvirtualdisplay import Display
import matplotlib.pyplot as plt
from IPython import display
import numpy as np
import pandas as pd
import torch
from torch import nn
from torch import optim
from torch.nn import functional as F
import typing as typ
from torch.distributions import Categorical
# from tqdm.auto import tqdm
from tqdm import tqdm # 下载notebook 仍能显示
import gym
import random
import os
from rich.console import Console
import warnings
warnings.filterwarnings('ignore')
cs = Console()
v_dispaly = Display(visible=0, size=(1400, 900))
v_dispaly.start()
print("gym.version=", gym.version)
def all_seed(seed=6666, env=None):
if env is not None:
env.seed(seed)
env.action_space.seed(seed)
np.random.seed(seed)
random.seed(seed)
# CPU
torch.manual_seed(seed)
# GPU
if torch.cuda.is_available():
torch.cuda.manual_seed_all(seed)
torch.cuda.manual_seed(seed)
# python全局
os.environ['PYTHONHASHSEED'] = str(seed)
# cudnn
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.enabled = False
print(f'Set env random_seed = {seed}')
def gym_env_desc(env_name):
"""
对环境的简单描述
"""
env = gym.make(env_name)
state_shape = env.observation_space.shape
cs.print("observation_space:\\n\\t", env.observation_space)
cs.print("action_space:\\n\\t", env.action_space)
try:
action_shape = env.action_space.n
action_type = '离散'
extra=''
except Exception as e:
action_shape = env.action_space.shape
low_ = env.action_space.low[0] # 连续动作的最小值
up_ = env.action_space.high[0] # 连续动作的最大值
extra=f'<{low_} -> {up_}>'
action_type = '连续'
print(f'[ {env_name} ](state: {state_shape},action: {action_shape}({action_type} {extra}))')
return
env_name= 'LunarLander-v2'
gym_env_desc(env_name)
env = gym.make(env_name)
class PolicyGradientNet(nn.Module):
def __init__(self, state_dim: int, action_dim: int):
super(PolicyGradientNet, self).__init__()
self.q_net = nn.ModuleList([
nn.ModuleDict({
'linear': nn.Linear(state_dim, 32),
'linear_activation': nn.Tanh()
}),
nn.ModuleDict({
'linear': nn.Linear(32, 32),
'linear_activation': nn.Tanh()
}),
nn.ModuleDict({
'linear': nn.Linear(32, action_dim),
'linear_activation': nn.Softmax(dim=-1)
})
])
def forward(self, x):
for layer in self.q_net:
x = layer['linear_activation'](layer['linear'](x))
return x
from torch.optim.lr_scheduler import StepLR
from typing import List, Dict, AnyStr
from functools import reduce
class REINFORCE():
def __init__(self, state_dim: int, action_dim: int, lr: float=0.001, gamma: float=0.9,
stepLR_step_size:int = 200,
stepLR_gamma:float = 0.1,
normalize_reward:bool=False):
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.policy_net = PolicyGradientNet(state_dim, action_dim)
self.policy_net.to(self.device)
self.opt = optim.Adam(self.policy_net.parameters(), lr=lr)
self.stepLR_step_size = stepLR_step_size
self.stepLR_gamma = stepLR_gamma
self.sche = StepLR(self.opt, step_size=self.stepLR_step_size, gamma=self.stepLR_gamma)
self.gamma = gamma
self.normalize_reward = normalize_reward
self.training = True
def train(self):
self.training = True
self.policy_net.train()
def eval(self):
self.training = False
self.policy_net.eval()
@torch.no_grad()
def policy(self, state):
"""
sample action
"""
action_prob = self.policy_net(torch.FloatTensor(state).to(self.device))
action_dist = Categorical(action_prob)
action = action_dist.sample()
return action.detach().cpu().item()
def batch_update(self, batch_episode: List[Dict[AnyStr, List]]):
l2_norm_squared_list = []
for transition_dict in batch_episode:
l2_norm_squared = self.update(transition_dict)
l2_norm_squared_list.append(l2_norm_squared)
self.sche.step()
return l2_norm_squared_list
def update(self, transition_dict):
reward_list = transition_dict['rewards']
state_list = transition_dict['states']
action_list = transition_dict['actions']
# 分数 normalize
if self.normalize_reward:
reward_list = (np.array(reward_list) - np.mean(reward_list)) / (np.std(reward_list) + 1e-9)
Rt = 0
self.opt.zero_grad()
for i in reversed(range(len(reward_list))): # 从最后一步算起
reward = reward_list[i]
state = torch.tensor([state_list[i]], dtype=torch.float).to(self.device)
action = torch.tensor([action_list[i]]).unsqueeze(0).to(self.device)
log_prob = torch.log(self.policy_net(state).gather(1, action.long()))
# Rt = \\sum_{i=t}^T \\gamma ^ {i-t} r_i
Rt = self.gamma \* Rt + reward
loss = -log_prob \* Rt
loss.backward()
l2_norm_squared = sum((p.grad \*\* 2).sum().item() for p in self.policy_net.parameters())
self.opt.step()
return l2_norm_squared
def save_model(self, model_dir):
if not os.path.exists(model_dir):
os.makedirs(model_dir)
file_path = os.path.join(model_dir, 'policy_net.ckpt')
torch.save(self.policy_net.state_dict(), file_path)
def load_model(self, model_dir):
file_path = os.path.join(model_dir, 'policy_net.ckpt')
self.policy_net.load_state_dict(torch.load(file_path))
def train_on_policy(
agent,
env,
num_batch=450,
random_batch=2,
episode_per_batch=3,
episode_max_step=300,
save_mdoel_dir='./check_point'
):
"""
on policy 强化学习算法学习简单函数
params:
agent: 智能体
env: 环境
random_batch: 前N个batch用random Agent收集数据
num_batch: 训练多少个batch
episode_per_batch: 一个batch下多少个episode
episode_max_step: 每个episode最大步数
save_mdoel_dir: 模型保存的文件夹
"""
EPISODE_PER_BATCH = episode_per_batch
NUM_BATCH = num_batch
RANDOM_BATCH = random_batch
MAX_STEP = episode_max_step
avg_total_rewards, avg_final_rewards, avg_total_steps = [], [], []
l2_norm_squared_list = []
agent.train()
tq_bar = tqdm(range(RANDOM_BATCH + NUM_BATCH))
recent_best = -np.inf
batch_best = -np.inf
all_rewards = []
for batch in tq_bar:
tq_bar.set_description(f"[ {batch+1}/{NUM_BATCH} ]")
batch_recordes = []
total_rewards = []
total_steps = []
final_rewards = []
for ep in range(EPISODE_PER_BATCH):
rec_dict = {'states': [], 'actions': [], 'next_states': [], 'rewards': [], 'dones': []}
state = env.reset()
total_reward, total_step = 0, 0
while True:
a = agent.policy(state)
if batch < RANDOM_BATCH:
a = env.action_space.sample()
n_state, reward, done, _ = env.step(a)
# 收集每一步的信息
rec_dict['states'].append(state)
rec_dict['actions'].append(a)
rec_dict['next_states'].append(n_state)
rec_dict['rewards'].append(reward)
rec_dict['dones'].append(done)
state = n_state
total_reward += reward
total_step += 1
if done or total_step > MAX_STEP:
# 一个episode结束后 收集相关信息
final_rewards.append(reward)
total_steps.append(total_step)
total_rewards.append(total_reward)
all_rewards.append(total_reward)
batch_recordes.append(rec_dict)
break
avg_total_reward = sum(total_rewards) / len(total_rewards)
avg_final_reward = sum(final_rewards) / len(final_rewards)
avg_total_step = sum(total_steps) / len(total_steps)
recent_batch_best = np.mean(all_rewards[-10:])
avg_total_rewards.append(avg_total_reward)
avg_final_rewards.append(avg_final_reward)
avg_total_steps.append(avg_total_step)
# 在进度条后面显示关注的信息
tq_bar.set_postfix({
"Total": f"{avg_total_reward: 4.1f}",
"Recent": f"{recent_batch_best: 4.1f}",
"RecentBest": f"{recent_best: 4.1f}",
"Final": f"{avg_final_reward: 4.1f}",
"Steps": f"{avg_total_step: 4.1f}"})
# agent.batch_update(batch_recordes)
l2_norm_squared_batch = agent.batch_update(batch_recordes)
l2_norm_squared_list.append(np.mean(l2_norm_squared_batch))
if avg_total_reward > batch_best and (batch > 4 + RANDOM_BATCH):
batch_best = avg_total_reward
agent.save_model(save_mdoel_dir + "_batchBest")
if recent_batch_best > recent_best and (batch > 4 + RANDOM_BATCH):
recent_best = recent_batch_best
agent.save_model(save_mdoel_dir)
return avg_total_rewards, avg_final_rewards, avg_total_steps, l2_norm_squared_list
# test sample env
env_name= 'CartPole-v1'
gym_env_desc(env_name)
env = gym.make(env_name)
all_seed(seed=NOTEBOOK_SEED, env=env)
agent = REINFORCE(
state_dim=env.observation_space.shape[0],
action_dim=env.action_space.n,
lr=0.01,
gamma=0.8,
stepLR_step_size=80
)
avg_total_rewards, avg_final_rewards, avg_total_steps, l2_norm_squared_list = train_on_policy(
agent, env,
num_batch=1600,
random_batch=2,
episode_per_batch=5,
episode_max_step=300,
save_mdoel_dir='./check_point'
)
fig, axes = plt.subplots(1, 3, figsize=(24, 6))
axes[0].plot(avg_total_rewards, label='Total Rewards')
axes[0].plot(avg_final_rewards, label='Final Rewards')
axes[0].set_title(f'{env_name} - Rewards Curve')
axes[0].legend()
axes[1].plot(avg_total_steps, label='Steps')
axes[1].set_title(f'{env_name} - Steps Curve')
axes[1].legend()
axes[2].plot(l2_norm_squared_list, label='L2 Norm Squared of Gradients')
axes[2].set_title(f'{env_name} - L2 Norm Squared Curve')
axes[2].legend()
plt.show()
此外,我在飞浆平台上也找了一个简单的策略梯度模型实现基于paddle的策略梯度模型实现,也是添加了绘制梯度L2范数/平方的部分,绘制出来的图奖励是收敛的,但是梯度L2范数剧烈波动,如下:
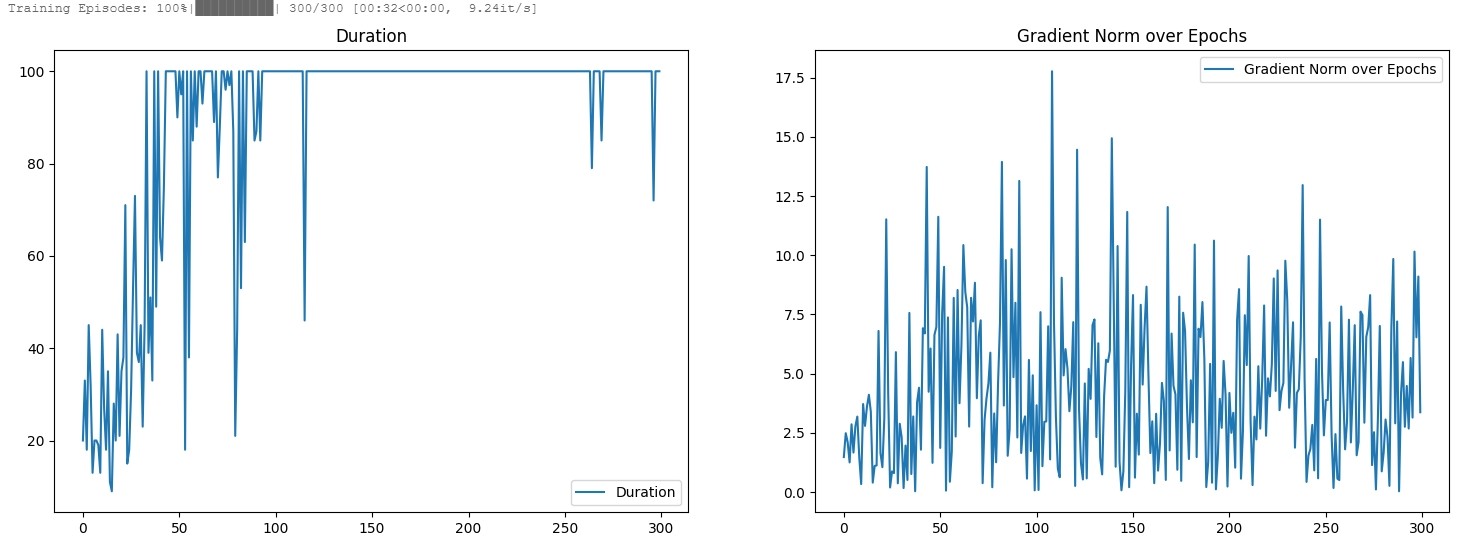
运行的代码如下:
# 简单模型 多轮次
import os
from itertools import count
import paddle
import gym
import numpy as np
from tqdm import tqdm
import paddle.nn.functional as F
from paddle.distribution import Categorical
import matplotlib.pyplot as plt
class PolicyAgent(paddle.nn.Layer): def init(self, obs_space, action_space): #初始化 super(PolicyAgent, self).init() #设样本批量数为batch,输入形状大小为[batch, obs_space],输出形状大小为[batch, 16] self.linear1 = paddle.nn.Linear(obs_space, 16) #输入形状大小为[batch, 16],输出形状大小为[batch, action_space] self.linear2 = paddle.nn.Linear(16, action_space) #log_probs列表用来保存历次行为的概率 self.log_probs = [] #rewards列表用来保存智能体每次与环境交互所产生的回报 self.rewards = []
def forward(self, x): #前向传播过程 #把输入x转化为tensor格式数据,并转成浮点数。 x = paddle.to_tensor(x, dtype="float32") #输入x经过linear1网络层运算,再接上relu激活函数 x = F.relu(self.linear1(x)) #再经过linear2网络层运算,然后在最后一个维度上接softmax函数 action_probs = F.softmax(self.linear2(x), axis=-1) #把上述的行动概率,转成分类分布 action_distribution = Categorical(action_probs) #从分类分布中进行抽样 action = action_distribution.sample([1]) #根据上述抽样的结果,求解该抽样结果的概率,对概率进行log运算 #每次得到的结果,追加到log_probs列表之中 self.log_probs.append(action_distribution.log_prob(action)) #返回行动值 return action.numpy().item() def loss_calculate(self, gamma): #损失函数 rewards = [] dis_reward = 0 log_probs = self.log_probs for reward in self.rewards[::-1]: #把rewards倒序排列 #计算折扣回报率 dis_reward = reward + gamma * dis_reward #每次从0位置插入,后进来的数排在前面。 rewards.insert(0, dis_reward) #把rewards转化为tensor,并对rewards进行标准化 rewards = paddle.to_tensor(rewards) rewards = (rewards - rewards.mean()) / (rewards.std()) loss = 0 for logprob, reward in zip(log_probs, rewards): #参考算法推导部分 action_loss = -logprob * reward loss += action_loss return loss
def clear_memory(self): #清除智能体记忆的函数 del self.rewards[:] del self.log_probs[:]
def train(): #创建平衡杆cartpole环境 env = gym.make('CartPole-v1') env = env.unwrapped env.seed(1) paddle.seed(1) obs_space = env.observation_space.shape[0] #状态空间,数值为4 action_space = env.action_space.n #行动空间,数值为2 #设置超参数 gamma = 0.9 episodes = 300 learning_rate=0.02 #模型初始化 model = PolicyAgent(obs_space, action_space) #优化器初始化 optimizer = paddle.optimizer.Adam(learning_rate=learning_rate, parameters=model.parameters()) #开始训练 duration = [] #记录每轮eposide所持续的时间 grad_norms = [] max_norm = float(5.0) for i in tqdm(range(episodes), desc="Training Episodes"): state = env.reset() #state的类型是ndarray for t in count():#一直不断地循环 action = model(state)#输入状态,输出智能体选择的行动 #环境会根据智能体的动作,输出下一个状态、回报、完成等信息 state, reward, done, info = env.step(action) model.rewards.append(reward) if done or t >= 100: #episode终止或玩游戏持续次数超过100 break #跳出本局循环 duration.append(t) #把本局的持续时间t,追加到持久期里面 if i % 250 == 0:#每过250次保存模型 paddle.save(model.state_dict(), './lup/'+str(i)+'.pdparams') #清零梯度 optimizer.clear_grad() #生成损失函数 loss = model.loss_calculate(gamma) #对损失函数求梯度,反向传播 loss.backward()
# 计算最后一层(self.linear2)的梯度范数 total_norm = [] for p in model.linear2.parameters(): if p.grad is not None: param_norm = np.linalg.norm(p.grad) total_norm += param_norm**2 grad_norms.append(param_norm)
#优化器用反向传播计算出来的梯度,对参数进行更新 optimizer.step() #清空智能体记忆 model.clear_memory() return duration,grad_norms
#训练智能体if name == 'main': duration, grad_norms = train()
fig, axes = plt.subplots(1, 2, figsize=(18, 6)) axes[0].plot(duration, label='Duration') axes[0].set_title(f'Duration') axes[0].legend() axes[1].plot(grad_norms, label='Gradient Norm over Epochs') axes[1].set_title(f'Gradient Norm over Epochs') axes[1].legend() plt.show()
是我绘制梯度L2范数/平方的代码错误了吗还是别的原因,现在无法绘制出一个收敛的梯度范数图。