
深度强化学习已经在许多领域取得了瞩目的成就,并且仍是各大领域受热捧的方向之一。本文推荐一个用 PyTorch 实现了 17 种深度强化学习算法的教程和代码库,帮助大家在实践中理解深度 RL 算法.
深度强化学习已经在许多领域取得了瞩目的成就,并且仍是各大领域受热捧的方向之一。本文推荐一个包含了 17 种深度强化学习算法实现的 PyTorch 代码库。

已实现的算法包括:
- Deep Q Learning (DQN) (Mnih et al. 2013)
- DQN with Fixed Q Targets (Mnih et al. 2013)
- Double DQN (DDQN) (Hado van Hasselt et al. 2015)
- DDQN with Prioritised Experience Replay (Schaul et al. 2016)
- Dueling DDQN (Wang et al. 2016)
- REINFORCE (Williams et al. 1992)
- Deep Deterministic Policy Gradients (DDPG) (Lillicrap et al. 2016 )
- Twin Delayed Deep Deterministic Policy Gradients (TD3) (Fujimoto et al. 2018)
- Soft Actor-Critic (SAC & SAC-Discrete) (Haarnoja et al. 2018)
- Asynchronous Advantage Actor Critic (A3C) (Mnih et al. 2016)
- Syncrhonous Advantage Actor Critic (A2C)
- Proximal Policy Optimisation (PPO) (Schulman et al. 2017)
- DQN with Hindsight Experience Replay (DQN-HER) (Andrychowicz et al. 2018)
- DDPG with Hindsight Experience Replay (DDPG-HER) (Andrychowicz et al. 2018 )
- Hierarchical-DQN (h-DQN) (Kulkarni et al. 2016)
- Stochastic NNs for Hierarchical Reinforcement Learning (SNN-HRL) (Florensa et al. 2017)
- Diversity Is All You Need (DIAYN) (Eyensbach et al. 2018)
所有的实现都能够快速解决Cart Pole(离散动作)、Mountain Car (连续动作)、Bit Flipping(动态目标的离散动作) 或Fetch Reach(动态目标的连续动作) 等任务。本 repo 还会添加更多的分层 RL 算法。
已实现的环境:
- Bit Flipping 游戏 (Andrychowicz et al. 2018)
- Four Rooms 游戏 (Sutton et al. 1998)
- Long Corridor 游戏 (Kulkarni et al. 2016)
- Ant-{Maze, Push, Fall} (Nachum et al. 2018)
结果
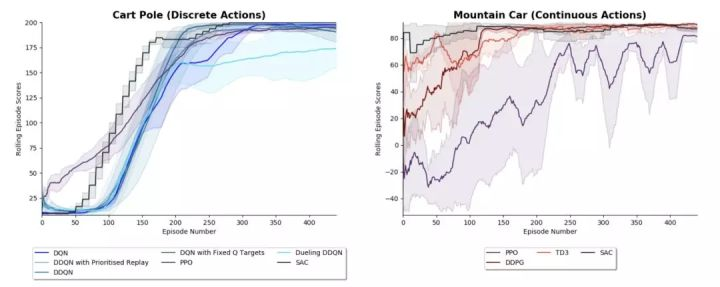
1. Cart Pole 和 Mountain Car
下面展示了各种 RL 算法成功学习离散动作游戏 Cart Pole 或连续动作游戏 Mountain Car 的结果。使用 3 个随机种子运行算法的平均结果如下图所示,阴影区域表示正负 1 标准差。使用的超参数可以在results/cart_pol .py和results/Mountain_Car.py文件中找到。
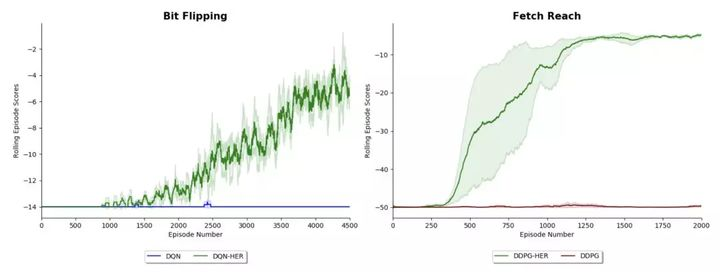
2. 事后经验重演 (HER) 实验
下面展示了 DQN 和 DDPG 在 Bit Flipping (14 bits) 和 Fetch Reach 环境中的表现,这些环境在论文 Hindsight Experience Replay 和 Multi-Goal Reinforcement Learning 中有详细描述。这些结果复现了论文中发现的结果,并展示了添加 HER 可以如何让一个 agent 解决它原本无法解决的问题。请注意,在每对 agents 中都使用了相同的超参数,因此它们之间的唯一区别是是否使用了 hindsight。
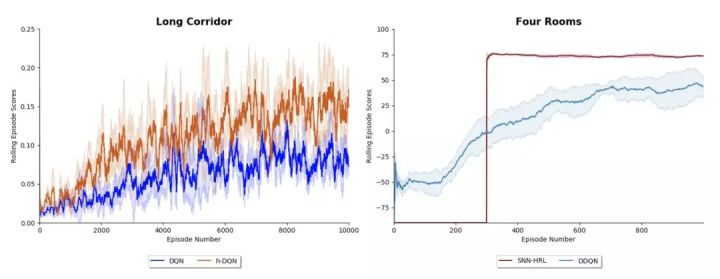
3. 分层强化学习实验
下图左边的结果显示了在 Long Corridor 环境中 DQN 和 Kulkarni 等人在 2016 年提出的 hierarchy -DQN 算法的性能。该环境要求 agent 在返回之前走到走廊的尽头,以便获得更大的奖励。这种延迟满足和状态的混叠使得它在某种程度上是 DQN 不可能学习的游戏,但是如果我们引入一个元控制器 (如 h-DQN) 来指导低层控制器如何行动,就能够取得更大的进展。这与论文中发现的结果一致。
下图右边的结果显示了 Florensa 等人 2017 年提出的 DDQN 算法和用于分层强化学习的随机神经网络 (SNN-HRL) 的性能。使用 DDQN 作为比较,因为 SSN-HRL 的实现使用了其中的 2 种 DDQN 算法。
用法
git clone https://github.com/p-christ/Deep_RL_Implementations.git
cd Deep_RL_Implementations
conda create --name myenvname
conda activate myenvname
pip3 install -r requirements.txt
python Results/Cart_Pole.py
新智元链接: https://zhuanlan.zhihu.com/p/83049006