文章来源: https://zhuanlan.zhihu.com/p/358560363
为什么我们要开源这个DRL库呢?
- 伯克利的RLlib ray:它是优点最多的DRL开源库:,实现了大量主流的DRL算法,支持分布式训练,支持三个深度学习框架(TensorFlow1、PyTorch以及TensorFlow2)。这个库明显的缺点是:代码量多,上手难,耦合度高,难改,安装需要大量依赖
- OpenAI的baselines:很早就开源的DRL库,训练很慢,且不稳定
- hill 的 stable baselines:baselines的不稳定催生了它。它使用了旧风格的TensorFlow 1,可读性低。并且训练依然不够稳定
- stable baselines 3:TensorFlow 1的不方便,催生了基于PyTorch的stable baselines 3。可惜里面是照着 TF1 直译的,且沿用了
- baselines的旧框架,不适应 2018年后的DRL算法。直到2021年3月,它依然不支持多GPU训练。
- 莫烦的教学代码:几年前中文社区只有他的教学代码,然而这是牺牲性能换来的可读性:训练几秒钟的入门环境,用他的代码要训练十几分钟,并且无法在稍高难度的环境下训练。这为推广强化学习做出了贡献,但我们需要新的DRL库。
- 「天授」:一年前中文社区开源了「天授」,可能自媒体当时的宣传太用力——近乎捧杀的宣传导致这个库在知乎的风评并不好,知乎:如何看待清华大学深度强化学习框架“天授”。而我们认为目前开源的库还不够好,因此才有了开发的动力。
还有一些比较好的库此处没有提及。我会找时间写一篇文章:评价主流的DRL库,告诉大家看哪些地方就能判断一个DRL库好不好。(ReplayBuffer、RL训练数据的吞吐、算法依赖关系、是否区分on-policy和off-policy、多进程的控制中心)
如果你觉得伯克利的RLlib ray学习成本高,那么我推荐你使用我们的「小雅:ElegantRL」
- “小”:只需要安装 PyTorch 和 Matplotlib 用于 网络训练 以及 画图协助调参,整个库只有4个 py 文件,并且tutorial版将一直维持在1000行代码以内,并保持与最新版有相同的变量名与结构,把学习成本降到最低。
- “雅”:代码优雅 可读性高,耦合度低 可移植性高。我们整理出DRL算法的基本模板,让它们都继承自一个基类。只要照着模板编写新算法,就能自动支持多进程训练。
- 高性能:ElegantRL在支持多进程训练后,她的最新版最要支持多GPU训练了。RL与DL的不同导致它的分布式不能照搬DL的多GPU训练模式。所以无法直接使用PyTorch 或TensorFlow 这些深度学习框架自带的多GPU训练模块。
我觉得除了伯克利的RLlib-ray,其他DRL库还需要做得更好,但是我又无法手把手教他们如何写一个更好的开源的DRL库,这是我们开源「小雅:ElegantRL」的初衷:希望有比RLlib-ray更容易使用的DRL库。我们还希望接下来开源它的分布式版本。
一句话概括强化学习(RL):Agent不停地与环境互动,通过反复尝试的方式进行学习,在一定的不确定性下做出决策,最终达到exploration (尝试新的可能) 与exploitation (利用旧的知识) 之间的平衡。
目录
- ElegantRL的特点
- ElegantRL的缺点(改进的方向)
- 总述:文件结构和函数
- 网络类的集合 net.py
- DRL算法的构建 agent.py
- 训练流程 run.py
- 效果展示 BipedalWalker-v3
- 回复Trinkle 的长评论
1. ElegantRL的特点
深度强化学习(DRL)在解决对人类有挑战性的多个现实问题中展示了巨大的潜力,例如自动驾驶,游戏竞技,自然语言处理(NLP)以及金融交易等。各种各样的深度强化学习算法及应用正在不断涌现。ElegantRL能够帮助研究人员和从业者更便捷地“设计、开发和部署”深度强化学习技术。ElegantRL的 elegant 体现在以下几个方面:
- 轻量:代码量低于1000行。
- 高效:性能向Ray RLlib靠拢。
- 稳定:比Stable Baseline 3更加稳定。
ElegantRL支持离散动作空间以及连续动作空间下的常用DRL算法。并且我们提供了十分友好的教程。
ElegantRL的缺点(改进的方向)
我们已经在本地实现了一些新功能,如分布式、新的算法。我们发现:在考虑分布式的整体设计的同时又要保持代码可读性比较困难。因此我们没有全部更新到最新版里,以后会陆续整理并发布到这里 ElegantRL/AgentZoo ,试用一段时间后,会移到最新版的文件夹中。
多GPU、甚至分布式:目前的版本和Stable Baseline 一样只支持multi-workers,还不支持多GPU训练(其实多GPU和分布式都做了,毕竟如果不做到多GPU甚至分布式训练,怎能说自己“性能向Ray RLlib靠拢”呢?)
算法少、缺少多智能体算法:我们清楚还有很多重要的DRL算法需要实现,例如 如何选择深度强化学习算法?MuZero/SAC/PPO/TD3/DDPG/DQN/等。可能最近会更新 V-MPO、MuZero 和 QR-DQN。特别要指出的是:我们还没有足够的经验去挑选出优秀的MARL算法,希望你们能向我们推荐如 QMix、MAPPO这类坚实的工作。
在ElegantRL中,我们基于Actor-Critic框架搭建深度强化学习算法,其中每一个Agent(即DRL算法)由Actor网络和Critic网络组成。利用我们完整简洁的代码结构,用户可以非常轻松地开发自己的Agent。代码已上传至 Github ElegantRL。
3. 总述:文件结构和函数
ElegantRL的“小”最直观的体现就是:整个库只有3个文件,net.py, agent.py, run.py。再加上一个env.py 用于存放与训练环境有关的代码。我们很开心能在Tutorial版用小于1000行的代码对一个完整的DRL库进行实现,这对想要入门深度强化学习的人能有莫大的帮助。
请注意,Tutorial版的ElegantRL 只是用来学习的。如果想要把ElegantRL当成生产工具,就需要使用最新版的ElegantRL,他的文件结构和函数保持了与 Tutorial版的统一。我相信这个库能对强化学习这个领域有贡献。
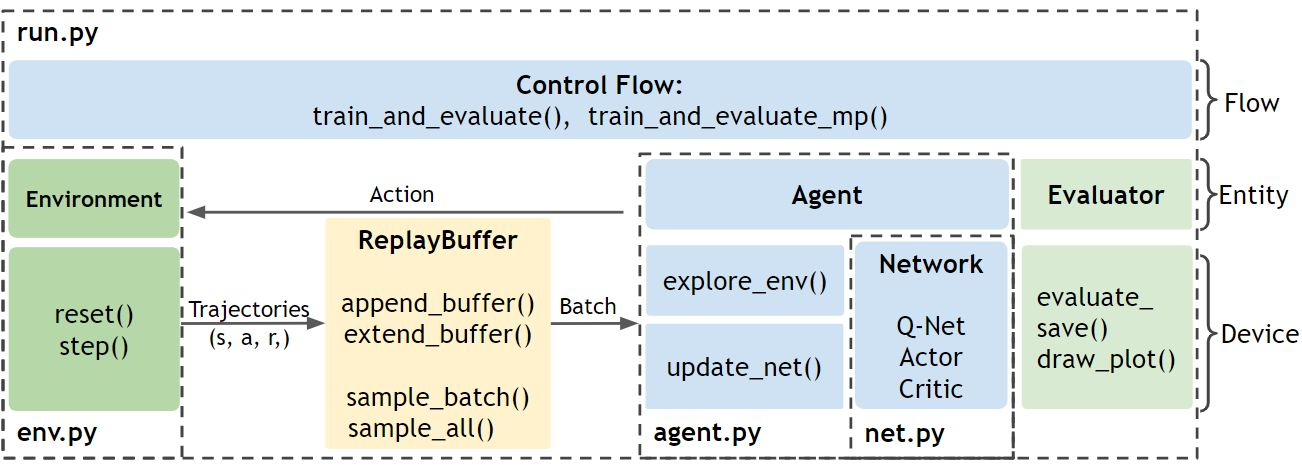
ElegantRL的文件结构如图1所示:
- Env.py:包含与Agent互动的环境
++ 包括PreprocessEnv类,可用于对gym的环境进行改动。
++ 包括自主开发的股票交易环境作为用户自定义环境的例子。
- Net.py:包含三种类型的网络,每个类型均包括一个网络基类,以便于针对不同算法进行继承与派生。
++ Q网络
++ Actor网络
++ Critic网络
- Agent.py:包含不同用于算法的Agent。
- Run.py:提供用于训练和测试的基本函数。
++ 参数初始化
++ 训练
++ 评测
从一个较高的层面描述这些文件之间的关系:首先,初始化Env.py文件中的环境和Agent.py文件中的Agent。Agent 既有包含在Net.py 文件中的网络,又与Env.py 文件中的环境进行互动。在Run.py 中进行的每一步训练中,Agent都会与环境进行互动,产生transitions 并将其存入回放缓存(Replay Buffer)。之后,Agent从Replay Buffer 中获取数据来更新它的网络。每一步更新之后,都会有一个评测器来评测并保存表现好的Agent。
问:强化学习算法需要训练多久?训练到什么程度就算收敛了?(经常有人在群里问)
答:与深度学习不同,不总是训练时间越长,智能体的性能越好。复杂情况下,不一定能观察到强化学习收敛。因此,强化学习并不是保存训练时间最长的,而是保存性能最好的model。其他DRL库缺少评测智能体性能的模块,这让我不满意。因此,ElegantRL里面有一个评测器 Evaluator 用来画出 learning curve,然后自动保存保存表现好的Agent。不用担心这会拖慢训练速度,因为我们开启了一个独立于训练进程的子进程利用于运行评测器。评测器还会画出其他指标,帮助我们调整超参数,或者修改自定义的环境或者算法。
4. 网络类的集合 net.py
net.py 文件存放了算法库会使用到的神经网络。我们将网络分为了三类:
'''Q 网络'''
class QNet(nn.Module):
class QNetDuel(nn.Module):
class QNetTwin(nn.Module):
class QNetTwinDuel(nn.Module):
'''Policy 网络(Actor)'''
class Actor(nn.Module):
class ActorPPO(nn.Module):
class ActorSAC(nn.Module):
'''Value 网络(Critic)'''
class Critic(nn.Module):
class CriticAdv(nn.Module):
class CriticTwin(nn.Module):
这为使用者微调算法提供了极大的便利。例如:把图片作为state输入神经网络时,我只需要到 net.py 将全连接层修改为卷积层即可。这种模式把深度神经网络与强化学习隔开,提高了代码的可读性。debug的时候,你会感激我:把net.py单独列出来,并把计算张量的计算加到网络里。类似的很多细节是我们从2019年总结至今的成果。因为,在之前我们一直没有正式发布「小雅:ElegantRL」,为的就是争取更多机会对整个架构进行调整。小雅不像其他库一样有很重的历史包袱。
5. DRL算法的构建 agent.py
agent.py存放了不同的DRL算法。在这一部分,我们将分别描述DQN系列算法和DDPG系列算法。ElegantRL中每一个DRL算法的Agent都继承自它的基类。在实现分布式的过程中,我们不能拖着太长的尾巴(太多的DRL算法),因此更多的DRL算法还不能马上与大家见面。我们已经实现了部分在这篇文章中提及算法: 如何选择深度强化学习算法?MuZero/SAC/PPO/TD3/DDPG/DQN/等 ,未来还会有更多。
DQN系列中的Agent类:
class AgentDQN:
class AgentDuelingDQN(AgentDQN):
class AgentDoubleDQN(AgentDQN):
class AgentD3QN(AgentDoubleDQN):
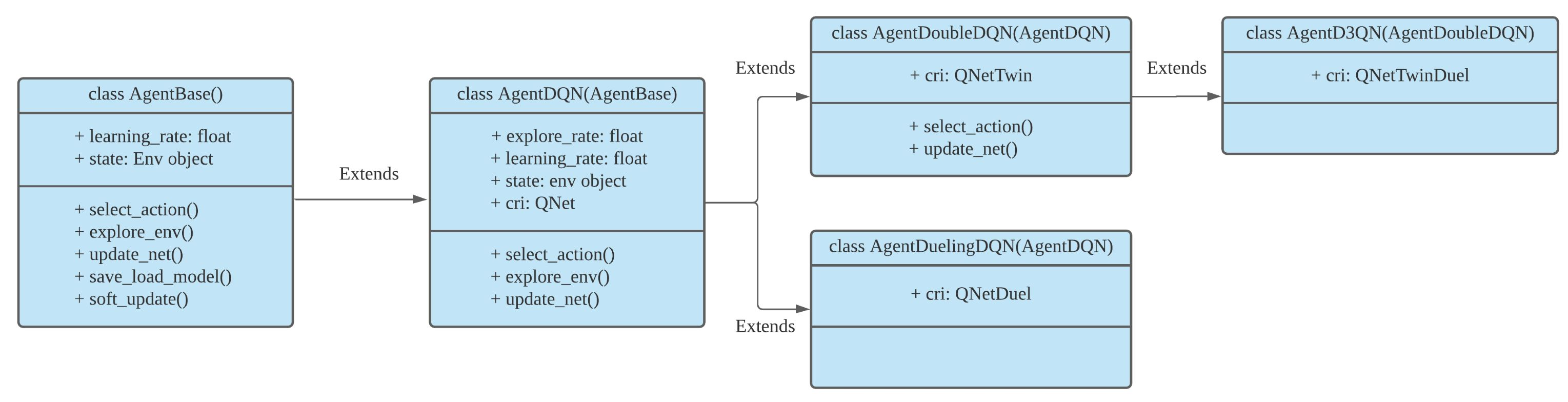
如图2所示,ElengtRL中DQN系列的继承层级关系为:
- AgentDQN:标准的DQN Agent。
- AgentDoubleDQN:为了减少过高估计而包含两个Q网络的Double-DQN,继承自AgentDQN。
- AgentDuelingDQN:采用不同的Q值计算方式的DQN Agent,继承自AgentDQN。
- AgentD3QN:AgentDoubleDQN和AgentDuelingDQN的结合,继承自 AgentDoubleDQN。
DDPG系列中的Agent类:
class AgentBase:
class AgentDDPG(AgentBase):
class AgentTD3(AgentDDPG):
class AgentSAC(AgentBase):
class AgentPPO(AgentBase):
class AgentModSAC(AgentSAC): # Modified
class AgentInterSAC(AgentBase): # InterXXX表示parameter sharing
class AgentInterPPO(AgentBase): # InterXXX表示parameter sharing
...
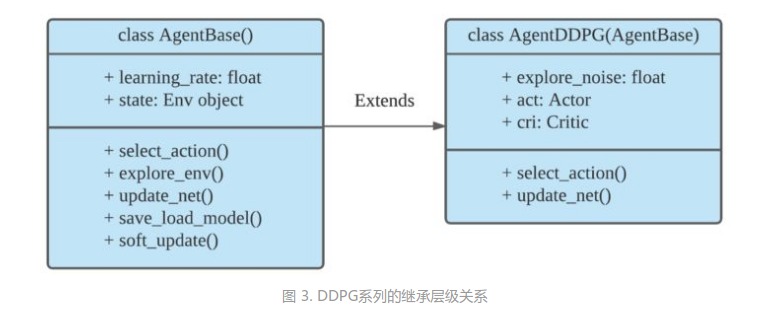
如图3所示,ElegantRL中DDPG系列的继承层级关系为
- AgentBase:所有A-C框架下Agent的基类,包括所有Agent共有的参数。
- AgentDDPG:DDPG Agent,继承自AgentBase。
- AgentTD3:采用新的更新方式的TD3 Agent,继承自AgentDDPG
在构建DRL算法的Agent时,采用的这种层级结构极大地提升了ElegantRL的轻量性和高效性。当然,用户也可以按照类似的方式构建自己的Agent。
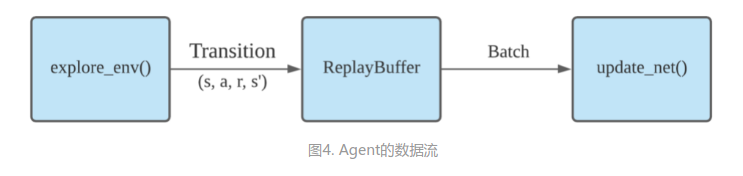
从根本上来说,每一个Agent都由两大基本功能构成。从数据流的角度可描述为图4的形式:
6. 训练流程 run.py
训练一个DRL Agent包含两大步:
agent.explore_env(...):
Agent在规定的步数内探索环境,产生transitions并将其保存至回放缓存(Replay Buffer)。
agent.update_net(...):
Agent根据回放缓存(Replay Buffer)中的一批数据来更新网络参数。
evaluator.evaluate_save(...):
评测Agent的表现,并保存具有最高得分的模型参数。
7. 效果展示 BipedalWalker-v3
BipedalWalker-v3是机器人研究中的一个经典任务:训练一个双足机器人尽快向前移动,同时消耗更少能量。由于它是一项连续动作空间下的简单任务,多数深度强化学习算法都能达到目标分数。我们提供这个环境供使用者快速体验算法。
经过与群友的磨合,选来选去,在大陆,只有 BipedalWalker LunarLander 这些基于Box2D引擎的env 最容易安装。MuJoCo 需要收费,PyBullet 的一些环境需要训练超过半小时,且对winOS支持不好,OpenAI gym 的一些toy env 太简单只需要训练几秒钟。
另外,在此我们想要特别说明,每个DRL算法都有它的适用场景,并且要在合适的超参数设定下使用高质量的代码才能展现出它的实力。例如在此任务下,SAC算法在超参数合适、且代码实现高质量的情况下可以通关;而PPO算法需要很大的采样数量(甚至要接近显存极限)才能通关。
接下来我们将展示如何利用ElegantRL一步一步训练能通关BipedalWalker-v3的深度强化学习算法。以下代码,你甚至可以在 Github ElegantRL 的根目录找到三个文件并直接运行。
BipedalWalker_Example.ipynb # 运行在Colab 的代码
Example_Demo.ipynb # 登陆Colab有困难的,可以在本地运行这段代码
Example_SingleFilePPO.py # 我们甚至提供了单个文件运行PPO算法,更容易上手
步骤1:安装ElegantRL
pip install git+https://github.com/AI4Finance-LLC/ElegantRL.git
步骤2:导入相关的库
ElegantRL
OpenAI Gym:用于开发和比较不同强化学习算法的工具
PyBullet Gym: OpenAI Gym的MuJoCo环境的开源实现
from elegantrl.run import *
from elegantrl.agent import AgentPPO
from elegantrl.env import PreprocessEnv
import gym
gym.logger.set_level(40) # Block warning
步骤3:指定DRL算法 AgentXXX 和环境 EnvXXX
args.agent:首先选定DRL算法,用户可以选择agent.py中的Agent
args.env: 创建并修饰环境,用户在env.py中既可以创建自定义的环境,也可以修饰OpenAI Gym和PyBullet Gym的环境
args = Arguments(if_on_policy=False)
args.agent = AgentPPO() # AgentSAC(), AgentTD3(), AgentDDPG()
args.env = PreprocessEnv(env=gym.make(‘BipedalWalker-v3’))
args.reward_scale = 2 ** -1 # 不同算法实现在该任务上的收益区间: -200 < -150 < 300 < 334
步骤4:训练并评测Agent
训练和评测过程都在这个函数中实现train_and_evaluate_mp(args)。其中包含了DRL中的两个对象:
AgentXXX()
EnvXXXXX()
其中包括用于训练的参数:
步骤5:测试结果
我们提供的一段代码,调用 env.render()把训练的结果渲染出来,并合成视频:
get_video_to_watch_env_render()
...
for i in range(1024):
frame = gym_env.render('rgb_array')
cv2.imwrite(f'{save_dir}/{i:06}.png', frame)
states = torch.as_tensor((state,), dtype=torch.float32, device=device)
actions = agent.act(states)
action = actions.detach().cpu().numpy()[0]
next_state, reward, done, _ = env.step(action)
state = env.reset() if done else next_state
...
我们提供了 Colab 的代码,帮助你运行双足机器人 BipedalWalker-v3 的demo,也许你能解锁出这个机器人的其他步态。如果你认为这个例子难度太低,该任务的进阶版BipedalWalkerHardCore-v3 是一个困难任务,环境中将会随机出现阻挡前进的台阶、沟壑以及大小箱子。由于它要求智能体在随机因素大的环境下训练(Dynamically Varying Environments 或者叫 非平稳环境 Non-Stationary Environments),因而只有少量的强化学习算法实现能达到目标分数。在gym 的 Leaderboard搜索这个环境的名字,可以看到有很多没有标注通关步数的算法 。
ElegantRL 就能通关这个很难的环境,选对了算法,用对了超参数的情况下,单GPU训练超过半天就能通关,有兴趣的可以挑战一下(用SAC、ModSAC 可以通关,而PPO比较难)。视频见:通关双足机器人硬核版 BipedalWalkerHardcore-v3_B站
很惭愧,只为强化学习领域做了一点微小的共享。如果github能给个星星,也许我们会利用更多空余时间尽快更新把其他DRL算法以及分布式,有推荐的算法可以在写评论区,特别是MARL算法,谢谢了。
我在下面的回复是我们内部讨论后给出的,与评论区的我个人的回复有所不同。
- 一个正常的这种开源项目至少是需要自动化的单元测试的
我们在本地有测试单元测试模块。我们准备在更新多GPU分布式之后,上传测试模块。
2.1 单文件行数如果超过1000行是不利于后续开发和维护的,
我们认同“单文件行数如果超过1000行是不利于后续开发和维护的”。我认为这个表述应该是“单个类行数如果超过1000行是不利于后续开发和维护的”。两个相同类型的类放在同个文件里是正常的做法。
2.2 而且repo里面存在大量的核心代码复制,通常是一系列bug的来源;
这里讨论的是耦合与解耦合。把重复出现的代码写成一个函数是软件工程中的常用做法,这可以使代码简洁,并减少代码量,代价是:提高了代码的耦合度。适当地进行这种操作是有益的,但是把控不好这个度,便会引入更加复杂的依赖关系。权衡之后,我们写出了现版本的ElegantRL。我们不接受这个修改建议。
self.cri_optimizer.zero_grad()
obj_critic.backward()
self.cri_optimizer.step()
self.soft_update(self.cri_target, self.cri, self.soft_update_tau)
# 把大量重复出现的代码写成一个函数:
def foo(self, obj_critic):
self.cri_optimizer.zero_grad()
obj_critic.backward()
self.cri_optimizer.step()
self.soft_update(self.cri_target, self.cri, self.soft_update_tau)
2.3 single file来完整地处理一整个算法流程,那么和stable-baselines3又有什么差别呢…?
我们不是 single file。
3.1 replay buffer有mp版本很不错,但是似乎只支持on-policy的系列算法,
我们不只支持on-policy的系列算法,还支持 off-policy,并且已经留出拓展空间,方便以后支持 MCTS系列(Model-based planning)。
3.2 而且replay buffer把state、action、reward写死了(用torch.as_tensor来flatten成array)这样其实挺不好的(其实这就是openai的做法),不利于后续拓展更多的环境
我们已经调研过现存的DRL算法,详见如何选择深度强化学习算法?MuZero/SAC/PPO/TD3/DDPG/DQN/等(已完成) ,实现DRL库时,我们让state、action、reward的储存模式分出这三类:on-policy、off-policy 以及 MCTS(Model-based planning),这样处理能让replay buffer足够灵活,有利于后续拓展更多的环境:明显地提高了数据吞吐速度,从而直接节省训练时间,详见DRL的经验回放(Experiment Replay Buffer) 用Numpy 实现让它更快一点 。这里走了与天授不同的技术路线,让用户选择吧。
- 实际上你会发现agent.update_*里面有很多相同的代码你写了好几遍,如果之后你想搞分布式训练的话(比如多个环境的交互)这一段所有的逻辑都得重写,天授的做法是专门拆出来一个Collector能够模块化地处理这件事
我们认为你们会遵守基本的沟通礼节(2.1/3.1/6.2),所以我们刚才必须阐明我们的立场。我现在讲一句,你们没有资格在ElegantRL面前说:“你们从自身经验出发 给ElegantRL的分布式提建议”。直到2021年3月,天授没有实现分布式。(我们过几周就会把本地的多GPU版本上传上去,然后再过几个月就会上传本地的分布式版本了)。若天授有升级为分布式的打算,它这一段所有的逻辑都得重写。这里提及的与 2.2 讨论的是同一件事情,详见上文“但是把控不好这个度,便会引入更加复杂的依赖关系。”
上面这段话的出处是:
我们认为你们会遵守基本的外交礼节,所以我们刚才必须阐明我们的立场。
我现在讲一句,你们没有资格在中国面前说:“你们从实力的地位出发同中国谈话”。——杨洁篪(阿拉斯加中美对话)
我们认为你们会遵守基本的沟通礼节,指的是:
2.3 single file来完整地处理一整个算法流程(我们不是single file)
3.1 似乎只支持on-policy的系列算法(我们不只支持on-policy系列)
6.2 (并不通用的)外部支持其实不应该作为核心代码出现在一个库中 (env.py 不是核心代码)
- 没有对done(Timelimit.truncate)的特殊处理
是的,这是我们做得不好,我们后续会处理它。谢谢这个一针见血的建议。
6.1 缺少基本的benchmark result,比如Atari和Mujoco(因为其实很多搞rL的人写论文基本上跑的除了自己弄的toy env之外就跑这几个benchmark)——事实上天授已经有对应的benchmark结果,比如可以在20分钟内用裸的DDQN来训练出一个PongNoFrameskip-v4(20+ reward),以及用1M的env step来超过spinning up提供的3M的benchmark结果(DDPG/TD3/SAC),详见thu-ml/tianshou
是的, 我们缺少基本的benchmark result。因为目前开源的DRL库中,支持多GPU的数量不多,所以我们希望在分布多GPU版本后发布后,再添加。我们不会使用收费的MuJoCo完成任何测试,这与开源精神相悖。我们暂时不打算和 spinning up 这种教学代码比较性能。我们将会和 实现了多GPU训练的库 比较(至少也和 实现了multi-workers的库 比较)。
6.2 还有像比如FinanceStockEnv这种(并不通用的)外部支持其实不应该作为核心代码出现在一个库中、不支持其他额外的功能比如RNN(我看过你的文章说RNN不好这我同意)、stack obs之类的小问题就不详细展开了
FinanceStockEnv所在的env.py 不是核心代码。选择FinanceStockEnv的理由:它只是作为一个例子,给自定义环境的用户一个可参照的Demo。它不依赖任何物理引擎,非常简单。此外,在DRL里通用的环境应该是什么?如果有更好的建议,我们会把通用的环境加入非核心代码 env.py
-1. 请不要天天嘲讽天授,在嘲讽之前请先比较一下双方的优缺点。我承认之前天授问题确实还挺多的,但是经过我们慢慢地推进,大部分问题已经得到落实,并且它有完善的社区反馈和跟进(新issue第一次回复时间平均小于30分钟,所有commit以PR的形式走并且有code review机制),这也就是它的github star至今还在不断上涨的原因
好的,我已经将「何须天授?彼可取而代也」用于入门的强化学习库 model-free RL in PyTorch ,这篇文章的链接从文章开头移除,只保留了知乎:如何看待清华大学深度强化学习框架“天授”。我们将会在更新多GPU版本后,参考PyTorch 以及 stable baselines 的Pull Requests 机制。在更新多GPU版本后再完善Pull Requests 机制很重要,这将保障Pull Requests 的代码不用在更新到分布式版本后由经历一轮大改,减轻历史包袱。
曾伊言问:目前天授距离你的1400行版本是否渐行渐远?一开始我们做这些库不就是看到别的库代码又长又乱才写的(不包括rllib,它长但不乱)? 我有一个群,里面有大量初学者,也有人私信我抱怨过看不懂那些复杂的依赖关系,你现在对天授的掌控力如何?
曾伊言问:我现在对elegantRL还有掌控力,因此我费尽心力推出了 tutorial版,单文件也是出于这方面的考虑。只要单文件内都是同类型的类,那么debug反而会简单。
@Trinkle
答:1.1.1 我确实想过这个问题,目前核心代码差不多是之前的两倍,但是实现的功能也差不多是之前的两倍,所以感觉这个应该还能接受……?如果不用其他功能的话可以不看对应的代码,不影响使用;并且外部的接口还是和原来几乎一致的。
@Trinkle
答:1.1.2“复杂的依赖关系”这一点我自认为现在并不复杂,至少和其他已有的popular RL repo比起来不复杂,当然和去年的天授比起来会复杂一些,但是想要支持一些新功能就得加一定的代码,这个是个tradeoff……你写到后面可能就会有感触了
是的,功能增加将带来代码量的上升。你提及“并且外部的接口还是和原来几乎一致”,我前文说的“历史包袱”指的就是这个。当原先的接口千锤百炼,那么它就可以保持稳定 。回复同前文。
曾伊言问: -1.2 我之前总结过各类DRL算法,确认了: DRL算法只需要分三类(on-policy off-policy MCTS), 因而replay buffer 可以用灵活性去换性能。类似的api设计,这些需要一个懂整个DRL训练流程的人去掌控,这样的人很少,天授从一个人设计到多个人设计之后,这方面做得如何?升级api是大动筋骨,你应该发挥你的影响力,给这一块来一轮升级才行。还有很多想说的,我会写在其他地方
@Trinkle
答:1.1.3 以及个人建议是最好遵循一下标准的软件工程的方法(公开单元测试、拆分多文件之类的),已有的规范还是挺重要的。debug的容易程度不是一个人说的算的,而是所有(各种)用户的实际感受,不是只有初学者。(当然初学者友好也是挺重要的,我们额外处理了各种corner case和报错信息为的就是能够让他们用起来比较丝滑)
@Trinkle
答:1.1.4 我还是有掌控力的,所有的pr都需要通过我的审核
好的,我们更新多GPU版本之后才会发布对应的模块,这与天授的安排不同。回复同前文。
@Trinkle
答:1.2 buffer api已经全部升级过一次了,在寒假的时候,半个月之前发布的新版本就是为了这个。主要是另一个学弟和我一起修改,不会有一些完整性的缺失
是的,这些改动都可以在Github上看到。