从论坛中受益匪浅, 前面刷twitter看到的,给大家也分享一下,也希望大家共同分享起来!
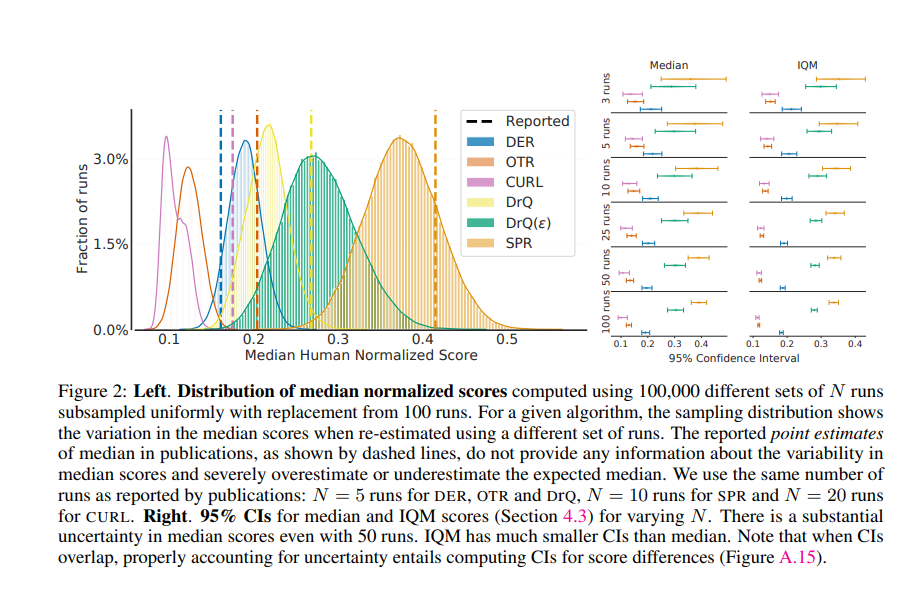
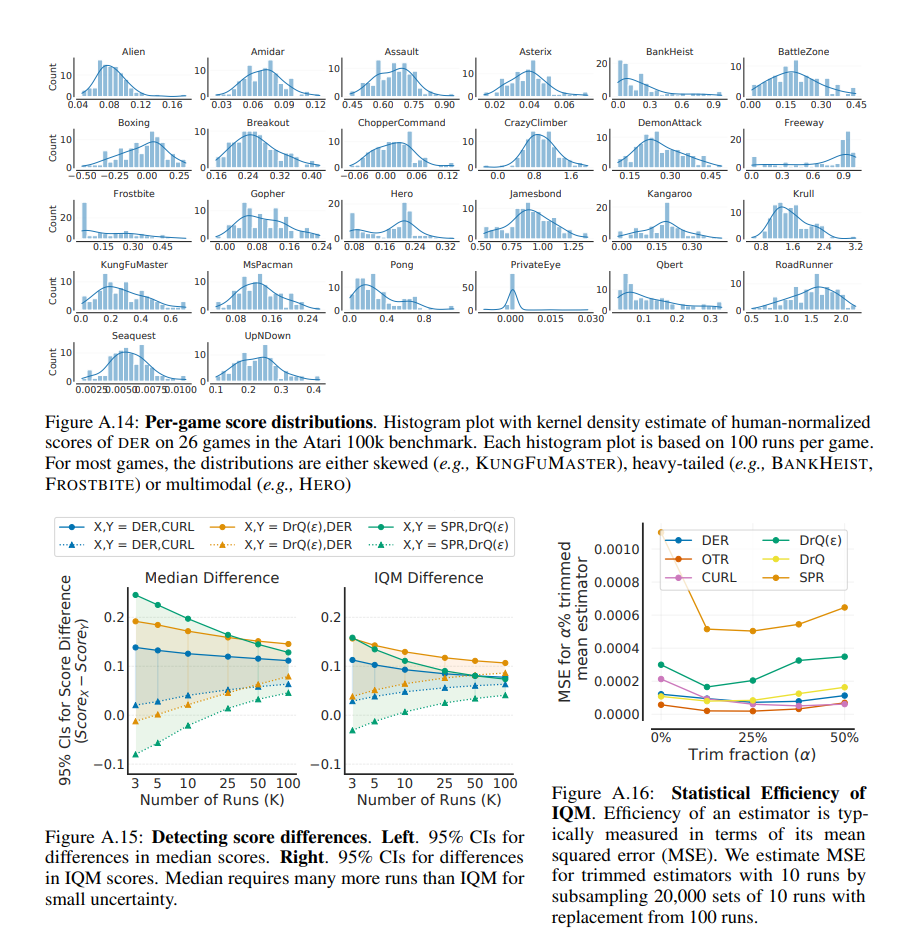
深度强化学习 (RL) 算法主要通过比较它们在大量任务上的相对性能来评估。大多数已发表的深度强化学习基准测试结果都比较了总体性能的点估计,例如跨任务的平均分数和中位数分数,忽略了使用有限数量的训练运行所隐含的统计不确定性。从 Arcade 学习环境 (ALE) 开始,向计算要求高的基准的转变导致每个任务只评估少量运行的做法,加剧了点估计的统计不确定性。在本文中,我们认为在少数运行深度强化学习机制中的可靠评估不能忽略结果的不确定性,而不会冒减缓该领域进展的风险。我们使用 Atari 100k 基准测试的案例研究来说明这一点,我们发现仅从点估计得出的结论与更彻底的统计分析得出的结论之间存在很大差异。为了通过少量运行提高该领域对报告结果的信心,我们提倡报告总体性能的间隔估计,并提出性能配置文件以说明结果的可变性,以及提供更强大和有效的总体指标,例如作为四分位数平均分数,以实现结果的小不确定性。使用此类统计工具,我们在其他广泛使用的 RL 基准测试(包括 ALE、Procgen 和 DeepMind Control Suite)上检查现有算法的性能评估,再次揭示了先前比较中的差异。我们的发现要求改变我们在深度强化学习中评估性能的方式,为此我们提出了更严格的评估方法,并配有开源库 rliable2 ,以防止不可靠的结果在该领域停滞不前。
Arxiv: https://arxiv.org/pdf/2108.13264.pdf
Github: https://github.com/google-research/rliable